
Football (“soccer”) is the most popular sport in the world, particularly in Europe, South-America, Africa and Asia. The most watched tournament is the UEFA Champions League, UEFA being the Union of European Football Associations. The UEFA Champions League is also the most-revenue generating tournament in football. Professional football has been troubled by multiple scandals in the past few years, including accusations of corruption and match-fixing.
Recently, the UEFA fell again under a cloud of suspicion. The 2013 Champions League draw ceremony for the quarter-finals resulted in the following four matches:
- Málaga—Borussia Dortmund
- Real Madrid—Galatasaray
- Paris Saint Germain—Barcelona
- Bayern München—Juventus
The outcome of the quarter-finals draw led to heated discussions in European sports programs on television and radio. Several sport journalists accused the UEFA of manipulation in order to make possible the commercially most interesting semi-finals and final. The most explicit accusations came from a former international soccer referee (details here).
It is quite remarkable that the Big Four of the eight teams avoided each other in the quarter finals. The Big Four are the two Spanish teams Barcelona and Real Madrid and the two German teams Bayern München and Borussia Dortmund. Moreover, it is remarkable that none of the Spanish teams was paired with the third Spanish team Málaga, an unattractive opponent for both Barcelona and Real Madrid. The quarter-finals draw kept open the possibility of a dream final between Barcelona and Real Madrid. What are the chances that this particular quarter-finals draw is rigged?
To answer this question, let us first calculate the probability that the Big Four avoid each other and neither Barcelona nor Real Madrid plays against Málaga when it is assumed that the eight teams are paired randomly. Under random pairing the Big Four avoid each other with probability
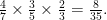
Since the draw ceremony involves eight teams, Málaga must be paired with one of the teams from the Big Four if the Big Four avoid each other. Hence, under the assumption of random pairing of the teams, the probability that the Big Four avoid each other and neither Barcelona nor Real Madrid is paired with Málaga is given by 
However, this is bad reasoning. The discussion is not about many tournament draw ceremonies, but about a particular soccer tournament ceremony for which there is reasonable ground to believe beforehand that the draw ceremony could be manipulated. In this situation it is appropriate to use the Bayesian approach. Bayesian analysis requires that before the draw ceremony takes place you quantify your personal belief that the draw ceremony will be manipulated.
Suppose you believe that the prior probability of a manipulated draw ceremony is at least 20%. Many soccer fans will consider a prior probability of 20% for a manipulated draw as a conservative estimate. By the formula of Bayes, your personal belief of a manipulated draw after hearing the result of the draw is given by a posterior probability of at least 68.6% if your prior probability is at least 20%. The easiest way to calculate the posterior probability is to use Bayes formula in odds form:

In our example the hypothesis H is the event that the draw ceremony is manipulated so that the Big Four avoid each other and neither Barcelona nor Real Madrid is paired with Málaga, 
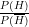

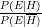
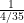
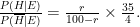
Since 

This posterior probability is equal to 0.6863 if your prior probability is represented by r=20%. The Bayesian analysis show that the suspicion voiced in the sports programs after the announcement of the result of the Champions League quarter-finals draw is certainly not unwarranted. Incidentally, in the end the final was not played between the two Spanish teams Barcelona and Real Madrid but between the two German teams Bayern München and Borussia Dortmund with Bayern München as winner.
This post emphasizes once again the importance of Bayesian thinking which is an indispensable part of statistical reasoning. Bayesian thinking is advocated in my book Understanding Probability (Cambridge University Press, third edition, 2012). This feature distinguishes my book from other introductory probability books and was praised in this book review.
I dare to say that the leading textbooks for introductory probability courses badly fail in the attention paid to the Bayesian approach. Students should be better trained to think in the Bayesian way. Every modern course on introductory probability should give greater recognition to the probabilistic ideas of Bayesian thinking and show that Bayes’ rule is the rational basis for answering probabilistic questions from real life.
Discover more from William M. Briggs
Subscribe to get the latest posts sent to your email.
“when it is assumed that the eight teams are paired randomly” – what does “randomly” mean in this context?
Rich,
Good question. I don’t know, but maybe Henk can tell us. How did the drawings happen? I mean the mechanism. I haven’t read the Daily Mail article yet.
Briggs,
You have an odd way of writing down probabilities. Would it not make more sense to arrange it this way?
(6/7) * (4/6) * (2/5) = 8/35
This way the logic of the calculation is apparent. This also assumes a certain “random” procedure.
I also see that you are assuming the existence of unconditional probabilities in your notation. Too much clutter otherwise, right?
Scotian,
By “you” presumably you mean Tijms?
Anyway, let us never forget that “random” merely means “unknown.”
Briggs,
In this case “random” means the selection procedure (picking names out of hats?). I am still curious as to your reasoning behind the arrangement of fractions that you have chosen.
Scotian,
I have chosen nothing. Have another look at the title.
Rich, Briggs
The use balls http://www.youtube.com/watch?v=DRdzvuhhLPs The urban legend says go that when they want to manipulate the result the right balls are warmer.
But how about if I have no idea if the ceremony is rigged? Oh yeah, right, r = 50% which means… that’s right P(H|E)=90% !!! What???
hahaha 😀 People has been sentenced to death with less certainty of culpability! Sometimes hunting Bayesians is like shooting ducks in a barrel 😉 But thanks for the story: bookmarked! 😛
‘let us never forget that “random†merely means “unknown.‒
Pah: one of the problems of teaching elementary statistics is that “random” means different things in different circumstances.
Briggs,
Yes I understand that (sloppy writing on my part), but my curiosity is still unsatisfied.
Let me comment on a few points raised.
Random pairing means that the draw does not discriminate beteen the teams so that all possible match schedules for the four matches are equally likely. In the Champions League soccer the match schedule for the quarter-finalsis determined by drawing each two balls from a bowl with eight opaque balls (each ball contains a piece of paper with the namr of the team).
The probability that the Big Four avoid each other can be calculated both as (4/7)*(3/5)*(2/3)and as (6/7)*(4/6)*(2/5). Both calculations use conditional probabilities and apply repeatedly the product formula
P(EF)=P(F)*P(F\E). To explain this, label the teams from the Big four as i=1,2, 3, and 4. For the first calculation, define Ak as the event that team k avoids the other three teams from the BIg Four and calculate
P(A1A2A3) as P(A1)*P(A1\A2)*P(A3\A1A2). For the second calculation define Bk as the event that team k+1 avoids the team 1 up to and including k and calculate P(B1B2B3) in the same way as P(A1A2A3).
Henk Tijms,
You haven’t shown how the stated fractions come from these equations. My fractions clearly come from the successive filling of bins with team names. They are readily visualized. I need a similar clear justification of your fractions. I have the feeling that you are using a sledgehammer to crack a walnut.
*sigh* Why would “frequentists” argue that because there are lots of soccer draws, that probability isn’t very small?
Rather, a frequentest would say that the probability, if the draw was fair, is what it is, about the same as the probability of rolling a 5 with two dice. Hardly a noteworthy event.
The Baysian analysis in this case adds nothing. Where logic is lacking is in backing up the statement, “Bayesian analysis show that the suspicion voiced in the sports programs after the announcement of the result of the Champions League quarter-finals draw is certainly not unwarranted.” Nonsense. That posterior probability is predicated on the assumption that the draw is fixed.
What you’ve proven here is nothing more than, “it’s not paranoia if everyone really is out to get you.”
Argh. To me, probability is a completely meaningless concept here. It was rigged or it wasn’t – it’s happened. If it was rigged, the probability that it was rigged is 1. If it wasn’t rigged, the probability that it was rigged is zero.
I suppose you would (one would, Tijms would) say that it means that, if I’d thought going in that I was 20% of the way from certain it wouldn’t be rigged to certain it would and the results then came in as they did, I am now 68.63% of the way from certain that it wasn’t rigged to certain that it was. Whatever you can construe ” per cent of the way from certain it wasn’t to certain it was” to mean…
And this informs me how? It enables me to make a better decision than shrugging my shoulders and saying “I dunno” how?
Reading this blog (which I invariably do), I’m becoming more and more reminded of a scene In Kill Bill Vol. 2 where Larry the boss is talking to Bud, his employee, and I’ll paraphrase: “What are you trying to convince me of? That statistical reasoning is as useless as an as _ _ _ole … right here?” (Points to elbow). “Well, guess what? I think you just f _ _ _ ing convinced me.”
Rob Ryan,
Oh my no. You could say of any proposition that it either was or wasn’t, therefore has probability 1 or 0. But no. Probability, like all logical argument, is conditional, as is proved here often. The probability of the drawing is therefore conditional on the premises which describe the drawing.
Also: “Either happened or not” is a tautology, always true, and therefore of no explanatory value as a premise (as also explained).
Yes, of course it’s a tautology. But I’m seeing no way in which the reasoning described here makes me better informed after the drawing than I was before. Were I in charge of and in complete control of the drawing, I’d have perfect information and probabilistic/statistical reasoning would be irrelevant. As I sit here, I find it equally irrelevant.
I’m starting to get the impression that the main point is that “the more you know about what has happened or will happen, the more you know about what has happened or will happen.”
It has just occurred to me that there is no reason to do the Bayesian calculation only once. The ~69% result is the new r and so on until you get to 100%. Thus any initial knowledge must lead to certainty. 🙂
Thinking about it more (rather than working as I should be doing) I suppose that if I were investigating for some responsible agency and had been suspicious that it was to be rigged, that this line of reasoning might give me reasonable cause to look for “hard evidence.” Perhaps it would be a basis for going before a judge to request a warrant.
OK, now I’m satisfied.
Hmm… the calculations and equations don’t show up in the Feedly reader.
Mr. Henk Tijms,
Why isn’t the evidence E simply the outcome of 2013 the quarter-finals draw? In this case, if I define “the draw is rigged†as described in the hypothesis H in this post, the posterior probability would be the same since P(E|H) = 1/12 and P(E| H complement) = 1/105.
Oh, Mr. Henk Tijms, excellent post!
“Suppose you believe that the prior probability of a manipulated draw ceremony is at least 20%.” If Mr Tijms thinks that the probability depends on what I believe, then doesn’t that make him a subjectivist?
But if “Many soccer fans will consider a prior probability of 20% for a manipulated draw as a conservative estimate”, then I suspect that this is the result of having seen many previous instances where things which were alleged to be done randomly turned out to be surprisingly fortunate from the point of view of the profits of those arranging the draw. In other words, under the hypothesis that less than 20% of the draws are rigged the past experience of cases favouring the league owners is high enough to have a low P-value.
Rob Ryan 15 August at 4:56 pm, you hit the nail on the head
“The urban legend says go that when they want to manipulate the result the right balls are warmer”, warmer than the left balls presumably. Football League draws, it’s a man’s game.
.
@Rich
warmer than the left balls presumably. Football League draws, it’s a man’s game.
haha… I finally understood the legend 😀
Mr. Tims: “It is quite remarkable that the Big Four of the eight teams avoided each other in the quarter finals.”
No, it’s not. By your own calculations, the probability is 8/35=0.229. And applying the Bayesian formulas with the prior of 0.2, your posterior is barely above 0.5. You have a very low standard for “remarkable”.
It’s interesting that you had to throw in the third Spanish team to pump your paranoia posterior up. I mean, suppose your’re a fan of Juventus, and your prior for rigging is 1/3, and you believe that this particular draw is the one and only draw that gives you no chance of winning. Then your posterior is 0.946. The evidence hasn’t changed; only the level of paranoia. And you get a much different result. Is this any way to do statistics?
I’m not a Bayesian, but I do think Baysian analysis can be very helpful in some situations. This isn’t one of them.
Mike, the accusations concerning the Big Four and Malaga are not mine but were expressed in various sports programs on television and radio. I just wanted to show that Bayesian analysis is useful to make clear that the sport journalists expressing their doubts are not paranoid, taking into account that in the past several UEFA Champions League draws were questionable.
First we have “remarkable”, and now we have “questionable”. Can you define these statistically? As I pointed out, if we stick just to the original claim involving the big 4, and a completely arbitrary prior of 0.2, the posterior is only slightly above 0.5. If you drop that prior down to 0.1, the posterior of the big 4 not meeting in the quarters is 1 in 3. So what’s the fuss? I see nothing questionable or remarkable.
Sure you can pump the posterior by arbitrarily increasing the prior, or by further (arbitrarily)qualifying the alleged non-randomness of the draw. But none of that changes the actual evidence. You’re just gaming the posterior.
Just for grins: what outcome would you have judged to be evidence that the process was not rigged? And BTW, I need to see a Bayesian proof.
You also need to take into account that you don’t always ask the question.
Imagine you watch a hundred draws, and most of them are boring. Boring, boring, boring, boring, …, boring, boring, b.. Hey! That one looks mighty convenient for someone!
The probability of it coming up by chance is some small number, say 10%. Not surprising in a run of hundreds of trials. But then you do your Bayesian analysis.
Any even with probability 1/10 shifts your information about the hypothesis -log(1/10) in the positive direction, or about 3 bits.
The information scale from -10 bits to +10 bits goes as follows:
0.1%, 0.2%, 0.4%, 0.8%, 1.5%, 3%, 6%, 11%, 20%, 33%, 50%, 67%, 80%, 89%, 94%, 97%, 98.5%, 99.2%, 99.6%, 99.8%, 99.9%.
So wherever you start on that scale, the observation shifts you 3.2 steps to the right.
But every time you see a boring result, that moves you some distance to the left. Or it would, if you ever asked the question. Not even statisticians spend much of their time looking at boring things.
So, we always have to ask the question: “Are we only doing this analysis because of the particular value the observation took?” If so, then there is a potential selection effect, in that we ignored all the boring observations that stepped us small amounts to the left, and only picked out the interesting one that moved us a long way to the right.