We started by assuming each X was measured without error, that each observation was perfectly certain. This is not always so for real X. It could be that the measurement apparatus itself does not produce error-free values, that instead the values come with some uncertainty. The values from satellites, for example, are like this: the values you see are actually output from a mathematical model which contains uncertainty. And it is often the case that the values of X from one time point to another are from different sources, even different locations. This, too, implies uncertainty, as we shall see. All proxy reconstructions have error.
Now, if each Xi is itself an average of, say, Yi,j , j = 1…m, where the Yi,j might be different fixed locations, then as long as each Yi,j is measured without error, we do not need to treat X any differently than we have been treating it. Those Yi,j can remain “hidden.” But if Yi,j is measured with error, that error must be accounted for in Xi. Averaging a bunch of Yi,j that are measured with error does not remove the error in the average: the average is inviolably subject to uncertainty. If you find yourself disbelieving this, then let m = 1. Aha! There the error is, plain as day. Therefore, if there is uncertainty in the Yi,j there is uncertainty in the Xi.
Another form of error is when then the locations and instrumentation change in time. This means that Xi is the average of Yi,j , j = 1…m, but that Xk (k n.e. i) is the average of, say, Wk,l , l = 1…n, where it might be that some of the locations/instrumentation in W match some of the locations/instrumentation in Y, but they all do not. This means that Xi and Xk are measuring different things, not just in time but in substance. It is possible to “map” Xk onto Xi+r, where k = i + r, but this requires a model. That is, if we want to talk of X everywhere being the same substance, we need to make sure they are all talking about the same thing. Doing so requires some kind of model, usually probabilistic. This model introduces uncertainty in the “mapped” Xi, even if, the Y and W are measured without error. If, as is likely for physical variables, Y and W are measured with error, then this error and the error due to “mapping” must be accounted for when speaking of X.
We began by asking
(2′) Pr(X1 = 0.43 | Error-free Observations ),
We noticed that X1 = 0.43, so that (2′) = 1 or 100%. But if there is error we must instead ask
(24) Pr(X1 = 0.43 | Error-filled Observations Z ),
where all we can say at this point is that (24) < 1 (it will also be > 0). The notation changes slightly here. We observe the value Z1 to be 0.43 and we ask what is the probability the actual, unobserved value X1 is the same. What we really need is this:
(25) Pr(X1 = 0.43 | Error-filled Observations Z & Mprob),
where we have some model, here assumed to be a probability model Mprob. Once we have it, we can answer questions like this
(26) Pr(X156 > X1 | Error-filled Observations Z & Mprob),
and
(27) Pr(X Decreased | Error-filled Observations Z & Mprob).
Let’s focus on (26) because it’s easier. It is no longer enough to look at the graph, which are now understood to be plots of Z and not X, and say whether X156 > X1. We don’t observe X, we see Z, so we can’t say with certainty whether this is so or not.
Since Mprob is a probability model, it will have a set of unobservable parameters about which we haven’t the slightest interest but which we must account for if we are to calculate (26). We certainly do not want to make a guess of those parameters and say that the guess of these parameters are really X (as many who work with proxies do). We don’t want to calculate something like (19) or (20) and make a decision whether some of these parameters should be set to 0 (or some other value). We absolutely, positively, 100% do not want to view the uncertainty in the parameters themselves as a substitute for (26) (as the BEST people did). This is the mistake most people make, especially when they are “reconstructing” temperatures from proxies. We are presented a long line of parameter estimates which do not say anything about (26) (or (27) or any other question about the real data).
Instead, we want to calculate (26) after removing all uncertainty we have in the parameters. In Bayesian terms, we say these parameters must be “integrated out.” The result, (26), is called a “prediction” because, of course, we are predicting what we do not see. ((26) is found from the “posterior predictive distribution.”)
All we can say for certain is that, if there is any measurement error, 0 < (26) < 1, where the limits are never reached. Different models of measurement error will give different values of (26). And all the same goes for (27). A glance at the plot is not enough to confirm that X really decreased or increased. And no matter what, (27) will be away from 0 or 1. There is no “straight line” or “trend” in (27), either. This is just a question if X decreased more often than it increased or stayed the same. We can add in a trend to (27), but that does not allow us to bypass modeling the measurement error: we must add these models together. And again, even if the trend+error model says one thing, that does not mean the plain error model is wrong.
Everything else I said about comparing probability to physical models still holds, except that now the physical models must be augmented by some notion of the measurement error. Usually this means the physical model is a physical+probability model. But however it is done, no interpretations must be changed. We just need to be sure we’re accounting for the measurement error.
We are finished. So if somebody now makes a claim such as “Temperatures have not increased over the last decade” we now know exactly how to verify this claim. Even better, we know how not to verify it.
Quod erat demonstrandum
Discover more from William M. Briggs
Subscribe to get the latest posts sent to your email.
Should’t it read “0 < (26) (26) > 1” in the pre-penultimate paragraph?
That got swallowed by the HTML parser. I wanted to say that it should read 0 .lt. (26) .lt. 1, rather than 0 .gt. (26) .gt. 1
What Sam said at 8:32
Sam,
Thanks. Typo. Fixed.
As a Padawan Learner of statistics, let me see if I can generate a simple example. Let me know if I’m on the right track, please:
Say we have a process and I develop a model for it: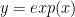 . Say that
. Say that  is measured with some error. If I am clever enough, I may be able to quantify the uncertainty in
is measured with some error. If I am clever enough, I may be able to quantify the uncertainty in  . But I cannot mistake that with the uncertainty of
. But I cannot mistake that with the uncertainty of  , for several reasons.
, for several reasons.
First, my model itself has uncertainty (error, residual). My formula only approximates the actual, real-world process. This uncertainty has nothing to do with the uncertainty in , and the two cannot be interchanged. Even if we can determine that
, and the two cannot be interchanged. Even if we can determine that  is measured with 0 uncertainty, my model still has uncertainty of its own. Conversely, the real world may be amenable to my simple formula and so my model itself may have almost no uncertainty, but
is measured with 0 uncertainty, my model still has uncertainty of its own. Conversely, the real world may be amenable to my simple formula and so my model itself may have almost no uncertainty, but  ‘s uncertainty propagates through and my results will have uncertainty.
‘s uncertainty propagates through and my results will have uncertainty.
Second, the uncertainty in is (in this example) actually magnified by the formula. An
is (in this example) actually magnified by the formula. An  results in my
results in my  having uncertainty of +0.29 and -0.26, which is larger and with a different symmetry than
having uncertainty of +0.29 and -0.26, which is larger and with a different symmetry than  . My formula could have a low inherent uncertainty, but the uncertainty in
. My formula could have a low inherent uncertainty, but the uncertainty in  has propagated through and been magnified by my model. If I tout the low uncertainty of my model in a paper, claiming that the uncertainty of my results must therefore be low, I am fooling myself.
has propagated through and been magnified by my model. If I tout the low uncertainty of my model in a paper, claiming that the uncertainty of my results must therefore be low, I am fooling myself.
(Sound right?)
Wayne – If that is right, it is probably the most concise description yet. Thanks. Also, thanks to Briggs for all of this. While I found the first three installments very quick and easy to grasp, I must admit I had to re-read the last two a few times to make sure I understood them correctly and my understandiing is the same as Wayne’s.
OT, thought you might enjoy this tidbit:
“… but from looking at the model variants so far climate model uncertainty dwarfs WG uncertainty.”
http://tomnelson.blogspot.com/2012/02/email-5134-dec-2008-phil-jones-is-much.html
Thank you. I’ve read several of your previous posts that say “this is what’s wrong with frequentist statistics.” I’m happy to read this one that covers some of how to get things correct.
Wayne,
My interpretation of the uncertainty problem may be a little different than what you describe.
The trap:
Take the measured Y and X as truth. Build your model Y=F(X) + E. Acknowledge that your model has an error (E). But E is already understated. And, your problems have just begun.
You test to show that you have sufficient evidence to say that F(X) “not null.” Once you have decided that the model passes this “significance test.” Your discussion turns on the perameters of F. Your estimated perameters are considered to be “best esimates.” X, Y and E can be quietly ignored at this time. The model is superior to reality.
Each transformation of the data introduces noise. The bad statistician recognises the error introduced at each step, decides that it is small enough to proceed to the next step, and ignores it thereafter.
All,
Sorry, a bit busy today. Thanks for all the questions and comments. My heart soars like a hawk! I’ll answer in the morning.
Meanwhile, if you’d be so kind, as requested in the first post of this series, please let others know about this, particularly those inclined to apoplexy.
Saw part 1, been busy and now you have been busy.
I toyed with the idea of raising a matter where I have no idea of your position but one where on many occasions I’ve thought, nope and wandered off.
It is not a valid time series, the values are PCM sample values, not data values for which a digital representation of data is being used. If you are dealing with lengths of chunks of wood, no problem but here sequence matters.
I don’t know whether I want to go anywhere with this.
@Doug M: In that sense, it’s like TV and movies, where the guy takes a low-res CCTV security recording and says, “Enhance!” and suddenly you can read the inscription on the perp’s watch, across the street.
@Doug M: Would you believe I’m working on the world’s most advanced data compression technique? I can compress any amount of data — of any kind — down to 1 bit. It’s *amazing*!
I *am* still working on the decompression technique, though I’m confident it’s just a matter of tweaking my algorithms a bit. Would you like to invest?
Wayne,
I also like the ability of those forensic scientists to find the reflection of the killer lurking in the background of an out of focus photograph.
Wayne: I dabble with compression algorithms from time to time, and recently had the idea of “exploring” certain irrational numbers for a specific sequence of bits, and then using the position in the irrational to represent the encoded data. I.e. say the irrational is Pi; maybe decimal place 30232424 to 3028888 have the same sequence of numbers as what you want.
After writing a program to zip through my irrational, i clicked go and waited, it took an hour or so of processing and I was able to find “will”. Then I abandoned all hope of seeing my dream realized anytime before the sun burns out. Still, hidden in that set, somewhere, might be an image of the Mona Lisa drinking a margarita.
Doug: believe it or not, there IS a way to do that, but it requires a lot of images and you need to know exactly how everything moved between frames. google “subpixel registration”.
Is there any measurement ever that is without error?
@George Steiner: Of course there is. Textbooks are full of them. And as far as I understand things, every scientific study that uses OLS regression assumes it. Proof by Authority. QED.
You mentioned that you would “latex this thing up” when it was over; do you have such a thing?