
Here it is, friends, the one complete universal simple function, the only function you will ever need to fit any—I said any—dataset x. And all it takes is one—I said one—parameter!
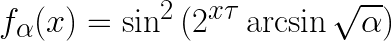
Magnificent, ain’t she? Toss away your regressions! Throw out your neural nets! Garbage your machine learning algorithms! This glorious little bit of math replaces them all!
Yes, sir, I do not idly boast. The function, the invention of one Laurent Boué, really does fit any set of data by it learning—they love this euphemism in computerland—that parameter α.
His paper is “Real numbers, data science and chaos: How to fit any dataset with a single parameter“. Thanks to MA for the tip. Abstract (ellipses original):
We show how any dataset of any modality (time-series, images, sound…) can be approximated by a well-behaved (continuous, differentiable…) scalar function with a single real-valued parameter. Building upon elementary concepts from chaos theory, we adopt a pedagogical approach demonstrating how to adjust this parameter in order to achieve arbitrary precision fit to all samples of the data. Targeting an audience of data scientists with a taste for the curious and unusual, the results presented here expand on previous similar observations [1] regarding expressiveness power and generalization of machine learning models.
The magic parameter is α, which is “learned” (i.e. fit) from the data. The τ you set, and “is a constant which effectively controls the desired level of accuracy.”
Before I show you how Boué’s magic function shows hypothesis testing—wee p-values and all that—is wrong (which I don’t believe he knew), here’s some of the datasets he was able to fit by tuning α.

Nifty, eh?
Now this isn’t a mathematical blog, so I won’t pester you on how that parameter can be calculated. The explanation in the paper is clear and easy to read if you’ve had any training in these subjects. Boué even has code (at github) so all can follow along. Let’s instead discuss the philosophy behind this.
First, this obvious picture. Before the dashed vertical line is the model fit in red; after the line is the model projection. The data is blue.

No surprise here. It has long been known that a function may be found to fit any dataset to arbitrary precision. What’s new about this work is that we only need this and no other function to do those (over-)fits, and that the function needs only one parameter. Cool.
As is also known, fitting past data well is no guarantee whatsoever that the model will predict future data at all. The model may fit perfectly, but monkeys could do a better job guessing the unknown. Like in this example.
Ah, yes. That has been known. But what is surprising is that this knowledge is also proof that hypothesis testing is nonsense.
Maybe it’s already obvious to you. If not, here’s the thick detail.
The moment a classical statistician or computer scientist creates an ad hoc model, probability is born. Just like in It’s A Wonderful Life with bells ringing and angels getting their wings. I do not mean this metaphorically or figuratively. It is literal.
It is, after all, what classical theory demands. Probability, in that theory, exists. It is as real as mass or electric charge. It is a ontic property of substances. And it has powers, causal powers. Probability makes things happen. I repeat: it exists. In that theory.
Granting this, and granting many of those who hold with the theory never remember it or think about its implications, it makes sense to speak of measuring probability. You can measure mass or charge, so why not probability? The data “contain” it. This is why frequentists, and even Bayesians and machine learners, speak of “learning” parameters (which must also exist and have “true” values), and of knowledge of “the true distribution” or the “data-generating distribution” (causal language alert!).
Hypothesis testing assumes the “true” probability on past data has been measured in some sense. If the model fit is good, the “null” hypothesis about the value of some “true”-really-exists probability parameter is rejected; if the fit is bad, it is accepted (though they use the Popperian euphemism “failed to be rejected”). The accepting or rejecting assumes the reality of the probability. You make an error when you accept the null but the “true” probability isn’t what you thought.
Anyway, it’s clear this universal function above will fit any data well. Null hypotheses will always be rejected if it is used, in the sense that the fit will always be excellent. The null that α = 0 will always be slaughtered. Your p-value will be smaller than Napoleon’s on his way back from Moscow.
But the model will always predict badly. The fit says nothing about the ability to predict. The hypothesis test is thus also silent on this. Hypothesis testing is thus useless. Who needs to fit a model anyway, unless you want to make predictions with it?
Maybe that hasn’t been noticed, because people sometimes pick models that aren’t as bad as predicting as this function is. This not-so-bad model picking creates the false impress that the test has “discovered” something about the “true” probability.
No. The first test of any model is in how well it conforms to its premises, from which it is derived. The closer the premises are to be necessarily true, the closer the model is to Reality. The more the premises are ad hoc, the further it is.
This means the only practical test of an ad hoc good model is its ability to predict. Not how well it fits, as “verified” by a hypothesis test. How well it predicts. That, and nothing more.
Subscribe or donate to support this site and its wholly independent host using credit card or PayPal click here
Discover more from William M. Briggs
Subscribe to get the latest posts sent to your email.
Yeah, I knew that.
And we knew you knew it, Haggie.
But can the computer processing the data see the fish it has drawn?
Wait… It didn’t draw the fish. It found a parameter that fits a pattern that I see as a fish.. But there is something a little sneaky in the examples. The point was plotted, but the line was not…
In Fluid Dynamics, our professor told us a story about going to a conference where someone presented their “Spectacular Formula”. They didn’t have 1 parameter. They had a never ending set of parameters. They did the linear algebra trick to fit their data into the equation. Someone at the pHD level presented this at a conference of engineers… The other phD’s in attendance were not quite able to explain the error of his ways.
That 1 parameter thing is fascinating..
Bizarre interpretation of hypothesis testing (per usual), which the paper does not mention hypothesis testing or p-values at all.
If I have a fair coin model and do 100 flips, I’d expect around 50 heads. I get 92, 87, and 90 heads in 3 separate experiments. From this evidence do I conclude the coin is fair or not? (not) Doing so will introduce an alpha (think of alpha in terms of a number of heads for which you conclude the coin is not fair).
Your “the null that ? = 0 will always be slaughtered”, “the model will always predict badly”, and “the fit says nothing about the ability to predict” are not true in a universal general sense, since we often find alphas that do not get rejected, find models that don’t always predict badly, and find where fits do say something about an ability to predict.
(Of course, such models based on data and experiments always seem to do better than religion’s track record with understanding the world.)
Did you not read this part of the paper too?
—
As should be clear by now, the parameter ? is not really learned from the training data as much as it is explicitly built as an alternative (encoded) representation of Xtrain itself. In other words, the information content of ? is identical (i.e. no compression besides a tunable recovery accuracy determined by ? ) to that of Xtrain and the model serves as nothing more than a mechanistic decoder.
—
Fun, but nothing like hypothesis testing whatsoever.
Cheers,
Justin
All,
Anybody who starts an argument with “assume a fair coin” has already lost. Ask them what fair means. Then get ready for fun! “Muh probability exists.”
The biggest tell that Justin doesn’t know what the hell he is talking about is his random and unnecessary dig against religion. He isn’t trying to convince you of something rationally, he is trying to convert you to his faith, which happens to be hypothesis testing.
The second tell is that he phrases all his reasoning in terms of parameters being real objects and probability being an actual part of reality, despite those being the points of contention. He should be saying “we know that parameters actually exist because…” but instead his arguments have the form “since we know the parameters exist we can conclude…”
He is like the naive apologist that tries to convince an atheist to convert by saying “how can you be an atheist, when the Bible says that ‘The fool says in his heart that there is no God?'”
Hmmm. Surprised that SAP Labs allowed this to be published …
The paper studies a magic-like, one-parameter mathematical function that reproduces the data, as the author states, the model serves as nothing more than a mechanistic
decoder. Assume no uncertainty. It doesn’t imply that hypothesis testing is useless in any ways.
The function is quite amazing, though not useful in making predictions. All data (possibly, all things) can be described mathematically. Is this a deterministic world?!
The tacit assumption in hypothesis testing is that we don’t know what model would work well for drawing inferences or making predictions. It is a way to judge, for example, whether a simpler model (nested in a complicated one) works as well as a more complicated one. Not perfect. Just one of the tools available.
Statistical learning assesses the goodness of models built using the training data set via various performance measures computed from the test data. A approach mainly for prediction and what statisticians or data scientists are using now.
Briggs, Justin lost. Do you get a prize?
Rudolph Harrier, you are hallucinating.
JH,
Yes.
@JH
“The tacit assumption in hypothesis testing is that we don’t know what model would work well for drawing inferences or making predictions. It is a way to judge, for example, whether a simpler model (nested in a complicated one) works as well as a more complicated one.”
That is certainly not how it’s sold to stats students.
Example: https://online.stat.psu.edu/statprogram/reviews/statistical-concepts/hypothesis-testing/examples
According to these examples (and the course) you can and should use hypothesis tests to extrapolate from small data sets to big ones. Nothing in here about *choosing what model to use*??!?
The claim is that by using a hypothesis test on “random” data (whatever *that* means), you can reliably determine traits of a ‘population’ from looking at a small number of ‘randomly’ chosen cases. That are the same, but somehow each is different?!?
Another one:
https://www.sagepub.com/sites/default/files/upm-binaries/40007_Chapter8.pdf
“Hypothesis testing is really a systematic way to test claims or ideas about a group or population.”
https://sites.pitt.edu/~super1/ResearchMethods/Arabic/HypothesisTestingpart1.pdf
“It is a statement about one or more populations. It is usually concerned with the parameters of the population. e.g. the hospital administrator may want to test the hypothesis that the average length of stay of patients admitted to the hospital is 5 days”
Seems like *how it is taught* is that you can make magical predictions just by satisfying some sort of statistical test using ‘random’ data.
I don’t understand. If the coin lands half the time on one side and half on the other it’s not rigged. If that happened for the last few zillion times can’t I expect it to happen for next bajillion?
I really have no opinion of the intricacies of statistical methods, but this silliness from Justin – “Of course, such models based on data and experiments always seem to do better than religion’s track record with understanding the world” – couldn’t pass without comment, demonstrating as it does a complete misunderstanding of metaphysics, and of the relative nature and limits of both religion and scientific “models based on data and experiments.”
Simplistic scientism is what Justin’s claim boils down to. A mediaeval Catholic like Dante (I cite him often lately, as I’ve been making my through his works in honor of the 700th anniversary of his death) had a far deeper and truer way of “understanding the world” than all of Justin’s post-Enlightenment materialists and scientists combined.
@PhilH “I don’t understand. If the coin lands half the time on one side and half on the other it’s not rigged. If that happened for the last few zillion times can’t I expect it to happen for next bajillion?”
That’s not what classical statistics is doing. Instead, first, you have to decide on a ‘null hypothesis’ which you *pretend* is true! “in the population of all coin flips ever ever ever forever, coins do not land on one side half the time and the other side the other half of the time”.
Then, you perform an “experiment”, where you flip a bunch of coins, where every flip is the same except that it is ‘randomly’ different from another coin flip. You then take these results and input them into a model which spits out a statistic of some sort. You then look at that statistic and see if it falls within the left or right edges of a normal distribution curve, and if it does, then, you decide that the thing you assumed to be true is ‘rejected’. Because reasons.
Simply *looking* is not good enough – coin flips apparently have some casual property called “probability” which can be discovered through these models supposedly.
Interesting article, but I can see why firm believers in ‘model training’ would find it unconvincing. Yes, the single-parameter function is differentiable in a pure math sense, but not in any practical sense, and certainly not in the sense that modelers need. To see this, put the equation into a spreadsheet and plot it with a resolution of, say, 0.1% of the distance between input data points. You’ll see that the value of the derivative explodes past the first few samples, because the function gyrates increasingly wildly between the measured data values.
If you attempted to use their single-parameter equation for the S&P prices to interpolate hourly prices between Oct 2018 and Feb 2019, the interpolation errors would span hundreds of dollars, just as it does for the extrapolation errors after Feb 2019. If a model can’t interpolate or extrapolate with any accuracy, I don’t see how using it as a counter-example is going to gain any traction with that target audience.
I don’t understand. If the coin lands half the time on one side and half on the other it’s not rigged. If that happened for the last few zillion times can’t I expect it to happen for next bajillion?
To expand on what Nate said, this is certainly a reasonable expectation but note that we do not need to talk about random variables, parameters, p-values, etc. to make the expectation reasonable. This is the shell game that hypothesis testing focused statistics does: it convinces you that your every day statements really mean a very specific statistical method, so that to deny that method would be deny your basic reasoning about the world.
But we can just as easily put your a predictive framework:
“Since I have observed that up to this point the coin flips have been evenly heads and tails, I will predict that in the future the coin flips will been evenly heads and tails.”
Note that there is some ambiguity in your statement of “half on one side and half on the other.” If it has been exactly half on one side and half on the other, for example if the result has varied between heads and tails every time for a zillion times, then we would probably make a predictive model saying “the coin flips will continue to alternate between heads and tails.” If the flips were roughly equal, such as having 500,000,117 heads and 499,999,883 tails in the first billion flips with no clear pattern for when heads lead to tails or vice versa, then we would say something like “we predict that over a large number of flips the ratio of heads to tails will be close to 1 (say, within a certain error for a large value of future flips.)” All of this basically captures your insight into what you expect to occur and gives a clear method for testing: do some more flips and see if your model continues to explain what happens.
Note that nothing is gained by saying something like “the coin flips must be observations of a random variable.” We have no way of knowing if the coin flips are deterministic or random (perhaps they are being affected by complex, but deterministic, environmental variables; perhaps they are fixed but being determined by a set, yet very long, string of 1’s and 0’s.) But it doesn’t really matter for your prediction: whatever the reason the flips are going the way they are going we expect them to continue to do what they are doing. Similarly it is not helpful to ask “what is the value of the parameter that determines the distribution of the random variable that the coin flips follow?” since that assumes that there is such a parameter determining things. And it definitely won’t help to ask “supposing our coin flips were produced by a random variable with a 50/50 distribution, what would be the probability that we would see what we saw?”, at least not to argue that the coin is “fair” and will continue to show this pattern in the future (since we would be assuming our conclusion to argue for our conclusion, i.e. begging the question.)
Now that I’ve gone through the paper, I can see why SAP Labs allowed it to be published. It looks more like a data compression algorithm than a predictive one. Nonetheless I’ll test it on some data sets to see how it performs.
An interesting take on the subject, however.
“Anybody who starts an argument with “assume a fair coin” has already lost. Ask them what fair means. Then get ready for fun! “Muh probability exists.””
But krakenstician, we assume a fair coin model and show evidence against that model. From experiments, we observe coins landing about 50% heads (relative freq of heads converges to flat line at .50). So that observation is what it means to say “a coin is fair”.
Still waiting for your evidence of miracles too.
Justin
“The biggest tell that Justin doesn’t know what the hell he is talking about is his random and unnecessary dig against religion. He isn’t trying to convince you of something rationally, he is trying to convert you to his faith, which happens to be hypothesis testing.”
Read again. Krakenstician started with religion, by bringing up magic and angels.
For you: we observe 92, 87, and 90 heads from 3 separate experiments on the same coin. Is the coin fair (50% heads) or not and what is your reasoning?
Justin
…and, your hero and fellow probability-theorist at work:
https://twitter.com/AccountableGOP/status/1444130224493445124
Got to hand it to you, Shecky. They pay you to do a job and you do it. A rare quality these days.
“But krakenstician, we assume a fair coin model”
Why? Explain why we should assume a model before we have data.
As for coin flipping, I wonder… is there a way to flip such and such to exclude the method of flipping itself from the experiment? Just looking at tail or heads supposes the method to flip the coin doesn’t matter. But it clearly does because you have to flip one way or another, and there are many ways…. So now the problem is to flip in a fair way. And then the problem becomes how to test this fairness again and you realize you are like the dog chasing its tail in endless loops. Does that imply all coin flipping is useless to give answers about the fairness of a coin? I am stuck with Zeno here…
“Boué’s magic function” (BMF) crushes all definitions of “science” as “goodness of fit.” Boué has proved that if all we are interested in is goodness of fit, then BMF is super-abundantly-sufficient. We do not need any other model, function, or equation. At all. We do not need hypothesis testing, p-values, confidence intervals, regression, confounders, hidden variables … none of it. All we need is BMF. We can iterate BMF as finely as we like, to produce whatever goodness of fit that we please. One BMF to rule them all; one BMF to find them… but I digress.
Milton Hathaway put his finger on the crux. Regarding data that we do not already have, “the function gyrates increasingly wildly.”
Proving Matt’s meta-point: what we are really interested in is our uncertainty in our predictions of data that we do not already have.
But krakenstician, we assume a fair coin model and show evidence against that model. From experiments, we observe coins landing about 50% heads (relative freq of heads converges to flat line at .50). So that observation is what it means to say “a coin is fair”.
Note that this can be interpreted as “we start, based on our knowledge of coins, by assuming a predictive model that says that for large numbers of flips of a coin about 50% will be heads and about 50% will be tails. We then see if this model makes good prediction in the future as we flip the coin more times. If it does not, say if the coin shos up heads 92 times out of 100, then we look for a better predictive model.”
That type of reasoning is exactly the approach that Briggs has advocated for repeatedly. Really, the only thing in Justin’s statement which is at odds with this approach is the aside “(relative freq of heads converges to flat line at .50)” since such a convergence is only possible with infinitely many observations which can never happen in real life, and thus such a statement only makes sense if we believe that the coin flips are “really” being generated by some sort of Platonic “random variable” that is more real than what we see in life.
But the truth is that Justin does not actually use the idea of relative frequency anywhere in his argument. Similarly, nothing that he has said in his examples requires that our reasoning be done by a consideration of whether we should “reject the null hypothesis” or consider a statistic like a p-value. It is a shell game; he puts forward a plausible bit of reasoning and then wants you to assume that the only way to formalize that reasoning is to use frequentist probability and hypothesis testing, even though those things are not necessary in any way to make sense of the reasoning and furthermore using frequentist methods DOES require accepting things which few people would normally accept (like mystical “random variables” which somehow affect the real universe.)
Of course Justin’s constant attacks on religion reveal his real purpose, and why he doesn’t care if his reasoning is honest or not. Finding a p-value is not something that he thinks reflects actual logical reasoning, it is instead a sacrament of his fedora-ist religion.
JohnK: “Milton Hathaway put his finger on the crux.”
Well . . . I was actually trying to make the opposite point. Maybe I should try to come up with a better example.
Suppose I measure the outdoor temperature at my house, once an hour, over the course of a day. Now I use those measurements for two purposes – first, to estimate the temperatures I would have measured on the half-hour, and second, to predict the hourly temperature measurements for the following day. Interpolation and extrapolation. Assume I know nothing about thermal energy flows, or much basic physics, and I decide that learning those things is too difficult and time consuming, so instead I’m going to choose some generic time-series modelling approach and train it with measured data. After some training with many days of half-hourly temperature measurements, the model ‘learns’ that the rate of temperature change (the derivative) is bounded, and starts to do a pretty good job of interpolating half-hourly data from the hourly data, but is still not great for predicting the hourly temperatures for the next day. I’m thinking that the model just needs to be trained on more data, and then the forecast will continue to improve. You tell me no, just take a look at this BMF model, it only has one parameter, and look how badly it predicts the future. I’m likely to retort that your model is crap, it can’t even interpolate worth a damn, your model tells me nothing about my model, go away.
On a side note, I take issue with what I perceive as an underlying theme in this discussion, that the only value in models is for prediction, where prediction is defined as extrapolation outside the bounds of the measured data. In engineering, most models interpolate, because engineers are trained to believe that extrapolation is likely to wind you up on the witness stand in a wrongful injury or death lawsuit. Generally there is a cost associated with taking measurements, so a mass-produced item might only have a very few measurements made on each item, usually at the nominal and the extreme operating points, and a model interpolates proper operation at all other operating points. The data that went into creating the model usually includes testing to destruction, something best avoided in the assembly line process.
Personally, I’m very suspicious of the concept of modelling based solely on training with data, without understanding the ‘first principles’ involved. Humans love shortcuts and magic, though, so this is a huge area of activity.
I imagine that most readers here are familiar with “thispersondoesnotexist.com” and similar websites. I don’t pretend to understand how it works, except that it uses a model that was trained on data, apparently without much, if any, understanding of how humans perceive faces. Useful, no doubt, especially for advertisers who don’t want to pay for face models and photographers. And it’s pretty good, but every once in a while it comes up with a face that looks broken, perhaps with a hole in the forehead or teeth where the eyes should be. For an engineer, such a tool couldn’t be used in a product design. “Yes, it messes up once in a while, but maybe only one in a thousand of our products will kill or maim you.” Or on the witness stand, “True, we don’t really understand how this thing works, so we couldn’t calculate a failure rate or bound the failure severity, it’s too darn complicated, so we just trained it on measured data.”
My wife thought this was great. She’s been in the financial industry 20 years now and has watched all these ridiculous models come and go. And yet still the big banks (she works at one of the largest) and finance houses trot out the latest and greatest thinking they’ve got crystal gazing figured out – at long last!
“Past performance is no guarantee of future returns.”
Rudolph,
“Note that this can be interpreted as “we start, based on our knowledge of coins, …”
based on our ***evidence from experiments***, not just knowledge.
Continuing,
“…by assuming a predictive model that says that for large numbers of flips of a coin about 50% will be heads and about 50% will be tails.”
Large number of flips. Sounds like you’re the frequentist here.
Continuing,
“Really, the only thing in Justin’s statement which is at odds with this approach is the aside “(relative freq of heads converges to flat line at .50)” since such a convergence is only possible with infinitely many observations”
You sound like one of those people that rejected calculus back in the day because one can never get infinitely close to something. Of course, we know calculus works extremely well (much better than religion). You tell me an epsilon > 0, and I can tell you about how many flips you’d need to flip the coin to get to its p, whatever p is.
In real life too, engineers don’t use pi, but an approximation pi*, where abs(pi-pi*}<t, where t is a tolerance they are OK with. You don't ever need literal infinite for convergence, despite what the krakenstician says.
Of course, in real life, we can just flip a coin and start to see it converge. If it doesn't converge to p, tell me your reasoning for why it would be say about .5 for 25,000 flips, but suddenly veer off to say .8 after that point? Why don't we observe that when we flip coins?
We can also simulate this fact now, in real life, on a computer, ever more times, and the logic works there too.
"Similarly, nothing that he has said in his examples requires that our reasoning be done by a consideration of whether we should “reject the null hypothesis” or consider a statistic like a p-value."
Then you didn't read too well. A p-value, despite krakenstats' arguments is not confusing. It is (a function of) the distance what you observe is from what you expect under a model. If I observe 92 heads, but expect 50, the distance is large (and the p-value small). How else are you comparing what you observe to what is expected under a model?
"using frequentist methods DOES require accepting things which few people would normally accept (like mystical “random variables” which somehow affect the real universe.)"
Random variable just means its outcomes follow a distribution, that one cannot predict an outcome with certainty. Since there are vast examples of this in real life, and the vast majority accept this, your "mystical" is easily rejected as nonsensical. For example, casinos, whose games require random variables, remain in business. The jury is also still out on any QM stuff too in the larger picture of the universe.
"Of course Justin’s constant attacks on religion reveal his real purpose, and why he doesn’t care if his reasoning is honest or not."
This blog and the post brought up religion (angels). But any religion or story (which are dishonest by strict definition) cannot help one determine the simplest of things like if a coin is fair or not, so they get rejected as being useful in this matter.
Justin