I apologize for the abruptness of the notation. It will be understandable only to a few. I don’t like to use it without sufficient background because the risk of reification is enormous and dangerous. But if I did the build up (as we’re doing in the Evidence thread), I’d risk a revolt. So here is the alternative to p-values—to be used only in those rare cases where probability is quantifiable.
Warning two: for non-mathematical statisticians, the recommendations here won’t make much sense. Sorry for that. But stick around and I’ll do this all over more slowly, starting from the beginning. Start with this thread.
Note in vain attempt to ward off reification: discrete probability, assumed here, is always preferred to continuous, because nothing can be measured to infinite precision, nor can we distinguish infinite gradations in decisions.
Our Goal
We want:
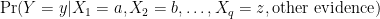
where we are interested in the proposition Y = “We see the value y (taken by some thing)” given, or conditioned on, the propositions X1 = “We assume a”, etc., and “other evidence”, which is usually but need not be old values of y and the “Xs”.
The relationship between the Xs and Y, and the old data, is usually specified by a formal probability model itself characterized by unobservable parameters. The number of parameters is typically close to the number of Xs, but could be higher or lower depending on the type of probability model and how much causality is built into it. The “other evidence” incorporates whatever (implicit) evidence suggested the probability model.
P-values are born in frequentist thinking and are usually conditioned on one of these parameters taking a specific value. Bayesian practice at least inverts this to something more sensible, and states the “posterior” probability distribution of the “parameter of interest.”
Problem is, the parameter isn’t of interest. The value of y is. Asking a statistician about the value of y is like asking a crazed engineer what the temperature of the room is and all he will talk about is the factory setting of the bias voltage of some small component in the thermostat.
The Alternative
The goal of the model is to say whether X1 etc. is important in understanding the uncertainty of Y. P-values and posteriors dance around the question. Why not answer it directly? Instead of p-values and posteriors, calculate the probability of y given various values of the Xs. One way is this:
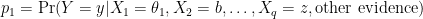
and
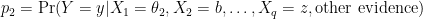
where 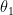
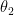
If p1 and p2 are far apart, such that it would alter a decision you would make about y, then X1 is important and can be kept in consideration (in the model). If p1 and p2 are close, and would not cause you to change a decision about y were X1 to move from
No Easy Answers
Gee, that’s a lot of work. “I have to decide about a, b, c and all the rest as well as
All this follows from the truth that all probability is conditional. The conditions are the premises or evidence we put there, and the model (if any) that is used. Whether any given probability is “important” depends entirely on what decisions you make based on it. That means a probability can be important to one person and irrelevant to another.
Now it’s easy enough to give recommendations about picking
Why is this method preferred? Decisions made using p-values are fallacious, they, and even Bayesian posteriors, do not answer the questions you really want to know, and, best of all, this method allows you to directly check the usefulness of the model.
P-values and Bayesian posteriors are hit-and-run statistics. They gather evidence, posit a model, then speak (more or less) about some setting of a knob of that model as if that knob were reality. Worst, the model and conclusions reached are never checked using new information. Using this new observable method, as is in use in physics, chemistry, etc. (though they might not know it), allows one to verify the model. And, boy, would that cut down on the rampant over-certainty plaguing science.
Variation On A Theme
Note: another method for the above is:

assuming (the notation changes slightly here) y can take lots of values (like sales, or temperature, etc.). If the probability of seeing larger values of y under
Discover more from William M. Briggs
Subscribe to get the latest posts sent to your email.
Pingback: Everything Wrong With P-Values Under One Roof | William M. Briggs
You must love EVOP then, Briggs. No statistical tests of any kind, frequentist or Bayesian. Pick a winner and move on.
You’ve glossed over the difficulty in computing p1= Pr(Y|X1,X2,X3,…,Xn) which can be computationally hard due to the size of the joint table. Things like Bayes Nets help but they also can be difficult with a large number of variables.
However, that doesn’t mean p-values would help.
Mike B,
He’s right though. If you can compute the conditional probabilities the answer is right under your nose. No need for any statistical tests (assuming the computing and comparing don’t count as “statistical tests”).
That also assumes you’ve magically selected the right X1..Xn set that are the only culprits for Y. Emphasis on the “only”.
DAV:
What I was getting at was Briggs’ comment that “even Baysian posteriors don’t answer the questions you really want to know”.
And you’re absolutely right, none of this does any good if you haven’t selected the right X’s.
Briggs, I could follow what you said (I think), but would love to see an example of the methods you propose on a real dataset, a worked out example.
I agree also that when you said “…model and conclusions reached are never checked using new information…”. in my limited expereince in the medical field, a lot of results of models are published, without anyone bothering to see of the results of the model hold true on data gathered after the study got published.
Cheers
Francsois
WB,
All interesting and I’m glad you are giving an alternative to p-values after your smack down. Often I need to compare two sets of data, the tradtioanl way would be the t-test with p-value — so if we can’t do that then how do we decide whether p1 and p2 are different enough — what of Cohen’s effect size — does it past the smell test
http://en.wikipedia.org/wiki/Effect_size
Tere is also (the difficulty with the proof by negation, i.e. if H0 False then H1 True. As if some other Hn did not exist. I can give an example from medical field. Epidural analgesia is a technique to decrease / eliminate pain (when possible) by injecting medications to epidural space at some level of spinal cord. A special really high tech catheter is passed through a needle . To make it happen the practitioner pushes the needle through skin, then through ligaments (fibrous tissue that holds bones together) and when that layer is passed the needle is in the epidural space. A little deeper and the needle will enter a subarachnoid space, i.e. space filled with cerebro-spinal fluid. After successful placement, a test is conducted to check where the tip of the catheter is located. The test consists of a dose of a local anesthetic (numbing medication) mixed with a small amount of epinephrine. The following reasoning is conducted during and immediately after the test dose:
1. If the tip is in subarachnoid space one will see immediate spinal block (effect of local anesthetic)
2. If the tip is in an epidural vein one will see transient increase in heart rate (effect of epinephrine)
3. If the tip is not in a vein nor it is in subarachnoid space one will see nothing thus the tip is in epidural space
The fact that it could be in some other space is neglected.
In experimental (biomedical) work that “indirectness” has to be addressed, particularly when causality is implied / claimed.
Andrew, the thing that I picked up here is that when you run an experiment you are driven by some question. You record the effect SIZE of your experimental intervention. Now, you know your staff that you test, you can tell how important the DIFFERENCE is. Are YOU impressed with it, does it make a difference in how others should do things? If yes, publish it with confidence intervals and good discussion. Am I right Professor Briggs?
Pingback: Fixes to problems in science: 3 happening now, 3 unlikely to happen soon | social bat .org — Gerald Carter
Pingback: Sobre la dificultad de los valores p | Biología Teórica