
From his page 55 (as before slightly edited for HTML/LaTex):
Consider the case of a binary event where the two outcomes are success, S, or failure F and we suppose that we have an unknown probability of success
. Suppose that we believe every possible value of
is equally likely, so that in that case, in advance of seeing the data, we have a probability density function for
= 1.
And 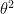
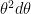
A simple argument of symmetry shows that the probability of two failures must likewise be 1/3 from which it follows that the probability of one success and one failure in any order must be 1/3 also and so that the probability of success followed by failure is 1/6 and of failure followed by success is also 1/6.
This is a contradiction or paradox and a glaring one which causes subjective Bayesians to cower (rightly). (I skip over the difficulties covered before with the idea of “independent trials”.) Where does the fault lie? Here:
Suppose that we believe every possible value of
What could that possibly mean? Nothing. Sure, it’s easy to write down a mathematical answer, but this does not make it a true or useful answer. First: how many numbers are there between 0 and 1? Uncountably many. It is impossible for any being short of God to assign a probability to each of these. Second: even if somebody could, because there are uncountably many answers, it is impossible that any should be the right one. Recall the probability of seeing any actual observation with any continuous (i.e. infinity-beholden) distribution is always 0, a daily absurdity to which we always shut our eyes.
We have jumped the infinity shark. Jaynes warned us about this (in his Chapter 15; though he didn’t always obey his own injunction). I think his caution goes unheeded because the calculus is so easy to demonstrate and to work with. What’s easier than integrating a constant?
As shown in the original series, we must begin with a real-world finite conception of each problem and only after we’ve sorted out what is what can we take a limit, and only then for the sake of ease and approximation. We must not fall prey to the temptation of reifing infinity.
(If there is sufficient interest, I’ll show the solution for Senn’s example another day: it’s a simple extension of the problem in the original series.)
Jaynes himself should have followed his own advice in the derivation of a (two-dimensional) normal distribution. He began with a premise (something like this; I don’t have the book to hand) when measuring a star’s position errors are possible in any direction. But he took “any direction” to mean a continuum of directions. This isn’t possible.
Suppose all we have to measure a star’s position (on a plane) is a compass which points only in the cardinal directions. Then our measured error can only be a finite number of possibilities. There would be nothing Gaussian about the probability distribution we use to quantify our uncertainty in this error. Right?
Next suppose we double the precision of our compass, so that it points eight directions. Still nothing Gaussian. Finally suppose we set the precision to whatever is the precision of today’s finest instrument. This would still be finite and non-Gaussian. We have nothing, and will never have anything, which can measure to infinite precision in finite time. This goes for star’s positions, salaries, ages, weight, and anything else you can think of. We’re always limited in our ability to see.
Acknowledging this “solves”—actually does away with—the long-standing problem of putting “flat priors” on (unobservable) parameters of distributions like the normal. These are called “improper” priors because they aren’t real probabilities, they’re only mathematical objects to which we assign an improper meaning. Since they aren’t real probabilities you’d guess people would abandon them. You’d guess wrong.
The other problem with infinite probabilities is measurement units: probabilities can change just by a change in unit, say from feet to centimeters, an absurdity if probability has a constant meaning. This problem also disappears when we remain this side of infinity.
Anyway, time to stop. Logical probability Bayes always lands on its feet. Plenty of mistakes enter with subjective Bayes, it’s true, or even in LPB when people (wrongly) insist on quantifying the unquantifiable. There are many misunderstandings when toying with infinity.
Thanks for this series William, they really help to understand better the Bayesian mind.
A star has to be somewhere if you can measure where it is. If you move along the compass points you will see that the star’s compass point is bigger than yours. At some point you pass the star and your compass point has become bigger than the star’s. So for any two points theta-1 and theta-2 which are related like this:
theta-1 < theta-star < theta-2
it follows that
Pr(thea-1 < theta-star) = 0, and Pr(theta-star < theta-2) = 1
While it would be impossible to pick the real number equal to theta-star, it is always possible to pick two numbers boxing in theta-star.
Now, the probabilities could be choosen such that Pr(theta) = (theta-2 – theta-1 ) / (theta-max – theta-min).
What’s the contradiction? I am unsure what you mean. 1/3+1/3+1/6+1/6=1 seems to work. If we assume Theta is one of 0,1/M,2/M,…M/M for some gigantic M, rather than continuous, aren’t we going to get a similar result? Won’t you just get Riemann sums that approximate integrals?
Briggs,
Maybe you should clarify the exact nature of the contradiction. You could apply it to this problem: Two chords are randomly placed on a circle. What is the probability that they will intersect?
William,
Find me two cords and a circle and we’ll have a go!
Briggs,
A cop out!
William Sears,
No, it’s not a cop out. The answer is insufficient information was provided. For even a logical solution to the problem, the lengths of both cords relative to the diameter of the circle must be known.
If the lengths are too small relative to the diameter of the circle the probability approaches 0.
On the other hand, if the lengths of the cords are much greater than the diameter of the circle then the probability approaches unity. In this case, the only way for the chords to not intersect is for them to land perfectly parallel. Assuming the chords are completely straight and inflexible, the odds of this would be 1/360 to one degree of precision. If the cords do not have to be straight, the odds against intersecting in this case get even lower.
For those interested in the exact nature of the contradiction, you might like to compare the two statements:
“It is impossible for any being short of God to assign a probability to each of these”
and
“Recall the probability of seeing any actual observation with any continuous (i.e. infinity-beholden) distribution is always 0”
Technically, these statements are not contradictory. But in combination they do have a rather interesting implication!
“On the other hand, if the lengths of the cords are much greater than the diameter of the circle then the probability approaches unity.”
The length of a chord cannot be greater than the diameter, as a chord is defined to be the straight line between two points on a circle.
It’s a well-known problem, in the spirit of Bertrand’s paradox. The idea is you can randomly select circle chords “uniformly” in several different plausible-sounding ways, and get different answers. It highlights the difficulty in defining uninformative priors.
Thanks NiV. MattS, you have misread the problem and your statements are incorrect. The only point of possible uncertainty is the definition of random, which is my challenge to Briggs. I want a statistician’s interpretation as I know what mine is. I have given this problem to my students in the past. There are calculus solutions and there are pictorial solutions that would have appealed to Martin Gardner.
In the chords on a circle problem my preferred definition of random is to place the ends of the chords randomly on the circumference. This sets the lengths. This relates to the point of this article in that there are an infinite number of set points of equal probability as assumed. This can be considered as arc positions on the circumference or as subtended angles – like a compass? With this clarification the problem has a well defined answer. Where is the paradox Briggs?
This is only a paradox if you insist that real numbers behave the same as a limited set of integers. The behaviour that I am talking about is the ability to pick a real number out of a bag with real numbers, as if real numbers are discrete things.
If you instead look at the properties that real number and integers have in common, then you can formulate this problem in such a way that the paradox evaporates.
Integers and real numbers can be ordered, you can always tell by comparing two real numbers which one is the smaller, if they are not identical. You can do the same for integers.
Now, you can formulate probability theory in terms of these comparisons, and you then have a theory that works for reals and integers.
For integers, there is also a formulation in terms of number of different states. That formulation doesn’t work for reals.
William S,
The chords-circles is an old problem because “random” doesn’t have a precise meaning, as you well know.
But I wasn’t joking either. The “experiment” isn’t one. You can’t “drop” chords on circles. There are no such things. This is why you have to be so careful in defining how to operate on these metaphysical creatures.
The point is not that we can never use infinity—I do not deny analysis!—but that we must always, in each problem, explicitly identify how we get there.
This is why normals (and other continuum distributions) are so queer. No matter what or where, the probability of making any observation given these is always 0. As in it is false you should see anything. This is never even close to an approximation in real life!
Briggs,
Yes, you definitely need to know how you got there. Not zero but, P(x)dx or for the circle dÆŸ/2Ï€. I sometimes think that you leave out important steps to make us think. But that’s alright, so do I.
“This is why normals (and other continuum distributions) are so queer. No matter what or where, the probability of making any observation given these is always 0.”
The probability for any point-observation is zero, but then as you say, you can’t actually make point-observations of infinite precision.
A continuous distribution does not just assign probabilities (all zero) to individual real numbers, it also assigns probabilities to intervals. (Strictly, sets in a sigma algebra – I’m assuming a Borel algebra for simplicity.) So if you think of a continuous distribution not as a probability density function on the real line, but instead as a function on the set of intervals, and then note that any real-world observation is of finite precision and therefore an interval too, we find that continuous distributions do assign non-zero probabilities to all possible observations.
You just have to be careful not to allow infinity in one place and forbid it in another.
Briggs, Any Bayesian
Thinking about it… Why there is a need for improper priors? Let’s say X follow a Normal distribution; can’t Bayesians just use something like Y = atan(X), work with Y within its finite boundaries and when done do X = tan(Y)?
This seems like a “proper” solution, why then go “improper”? There must be a reason but I don’t know enough about Bayesian ways so thank you to anyone answering!
Fran (I only read your comment; sorry everybody; very busy),
You “need” the improper priors on the parameters of model, else you can’t put a “probability” on every single thing the parameters can be. Oh, there’s all kinds of hand waving about “sequences” of priors to cover up the mathematical embarrassments.
But none of these solve the metaphysical problem of assigning probabilities to impossible events.
To read about the math, just about any text in Bayes will work. Probably best is Bernardo and Smith.
To see philosophical problems, see chapter 15 in Jaynes. And look up some of Jim Franklin’s work. He has a terrific book on probability before math. Science and Conjecture or something (I just came from a wine-soaked picnic or I’d tell you exactly).
Update: Franklin was David Stove’s student. See his books on Induction; esp. second one. Masterful.
I think Fran is wondering why don’t we, for example, if mu is the mean of an unknown gaussian, assume atan(mu) has a uniform prior distribution on -pi/2 to pi/2. This would make certain values of mu more probable than others a-priori. So what? With enough data, will it make a difference?
It’s not clear to me how assuming a finite number of possible events helps in the case of the mean of a gaussian. Do you need a list of possible values before you begin? I could see choosing as the possibilities any number that can be represented using IEEE 754 double precision. This set, like any other finite set, is bounded, so it is possible that it could fail. Further, is it ok to assume equal probability to all these numbers even though they are not equally spaced out?
For the “two chords problem” choose 4 points at random on the circle. Consider connecting pairs of these to create two chords. There are 3 ways to do this, one of which produces crossed chords. Thus the probability is 1/3.
Yes, I understand Bertrand’s “paradox,” but I do like the above argument.
Briggs,
Thanks for the references!! I am checking on Bernardo and Smith, in section “5.6.2 Prior Ignorance” they explain there is no a fully established way to state an “uninformative” prior. They say and I quote: “However, there can be no final word on this topic!”
They believe that ignorance is relative to the problem and that, for the same information, changing the problem changes the uninformative prior… which makes you wonder why to call it uninformative at all if it changes with the information coming from the problem, but anyway.
SteveBrooklineMA,
Yeah… I think you are right. I think that must be the reason.
If they go “proper” they need to make a pick which would be Subjective, and if they don’t make the pick the need to go “improper” which is improper?… conundrum.
Fran,
Apropos to all this is the post the day after this one. On direct and inverse probability.
All,
Two more days left of class!
“Thinking about it… Why there is a need for improper priors?”
Strictly speaking, there isn’t a need. It just makes the maths easier.
The way we generally approach a physical problem is to first build a mathematical idealization of it – a mathematical model. The model is strictly-speaking incorrect; it involves all sorts of objects and concepts that do not exist. Point particles, rigid bodies, incompressible fluids, infinitely divisible space and time,… the real world doesn’t work that way. The reason we do it is to make the mathematics easier, without losing anything important.
The idealizations are not really asserting that the limit applies, or that you can act for all purposes as if it does. It’s generally code for saying some quantity is “small enough to ignore”. We can calculate the collisions of particles of finite size and elasticity, but if the particles are small enough, it doesn’t really affect the answer. You get a bunch of extra, messy terms in the equations, as a consequence of the non-zero size of the particle, but they’re all tiny compared to the major effects. So we idealize on a point particle to make the messy terms go away. But the idealizations you can legitimately make depend on the question you’re asking, so you have to be careful.
Improper priors, such as setting a uniform distribution on the whole real line, are an idealization that says the real prior is flat over a big enough range to cover any feasible value. If your measuring instrument gave a reading in the neighborhood of 10^(10^1000) you’d be very surprised – you do actually have a narrower prior. But it would involve extra work and messy details to actually estimate and incorporate it, so you just assert that it’s broad enough to accommodate the required range without specifying what that range is. Similarly, you can replace a continuous Gaussian distribution with a discrete Binomial one, or some even more complicated variation on it. But all that does is to make the calculation incredibly messy and difficult, and gives virtually the same answer.
But if you were willing to include all the messy details, you could avoid having to use improper priors altogether.
—
Having thought about it for a bit longer, I think the issue Briggs is objecting to is the way trials that are independent when calculated with forward probability become dependent when calculated with inverse probability. The two coin tosses are independent, the outcome of one does not affect the probability of either outcome of the other. But when you look at Bayesian probabilities, seeing the outcome of the first changes your beliefs about the second. Because your typical coin is biased, seeing the first outcome tells you which way the bias swings. If you don’t think carefully, this may seem like a contradiction.
The problem is that you are using two different mathematical models of the physics, and variables in each that look like the same thing are actually different objects with different mathematical properties.
In the direct calculation, you have two variables X1 and X2 representing the coin tosses of a biased coin, and X1 is independent of X2. In the indirect calculation the model has *three* variables: X1, X2, and the probability of heads P. The variables corresponding to the previous case are actually the conditional distributions X1|P=p and X2|P=p, and these are independent. But both X1 and X2 separately depend on P, and hence X1 is correlated with X2. You might suppose that because X1, X2 are the “coin toss outcomes” in both models that they are the same thing, but in fact one set are the coin toss outcomes for a fixed common bias, and the other is the coin toss outcomes taken over all possible biases. Learning about X1 tells you something about P which tells you something about X2. In the direct model the coin bias p is already known so there is nothing to learn.
This has nothing to do with infinity, or continuous distributions. It’s about confusing similar-sounding concepts in two different inequivalent situations.
Pingback: Objective Bayes Vs. Logical Probability (Vs. Frequentism) | William M. Briggs