
Well, just a little (all emphasis mine and joyfully placed):
Statistical significance is junk science, and its big piles of nonsense are spoiling the research of more than particle physicists…
But here is something you can believe, and will want to: Statistical significance stinks…
The null hypothesis test procedure is not the only test of significance but it is the most commonly used and abused of all the tests. From the get go, the test of statistical significance asks the wrong question…
In framing the quantitative question the way they do, the significance-testing scientists have unknowingly reversed the fundamental equation of statistics. Believe it or not, they have transposed their hypothesis and data, forcing them to grossly distort the magnitudes of probable events…
They have fallen for a mistaken logic called in statistics the “fallacy of the transposed conditional.”
And that’s just the first part. I couldn’t finish the second because my eyes were overflowing with happy tears.
Ziliak and pal Deirdre McCloskey, incidentally, co-authored the must-read The Cult of Statistical Significance.
Cult, they say. Cult because there is an initiation at high price. Cult because statistical “significance” is invoked by occult incantations, the meaning of which has been lost in the mists of time. Cult because these things can not be questioned!
The p-value is a mysterious, magical threshold, an entity which lives, breathes, and gazes sternly over spreadsheets; a number gifted to us by the great, mysterious god Stochastikos1. It was he who decreed that great saying, “Oh-point-oh-five and thrive; Oh-point-oh-six and nix.”
Adepts know the meaning of this shorthand. So 0.050000001 is sufficient to cast a result outside the gates where there is weeping and gnashing of teeth. Yet 0.04999999 produces bliss of the kind had when the IRS decides not to audit.
Members cannot be identified by dress but by their manner of speaking. Clues are evasiveness and glib over-confidence. They say, “The probability my hypothesis is true is Amen” when what they mean is “Given my hypothesis is false, here is the value of an obscure function—one of many I could have picked—applied to the data assuming the model which quantifies its uncertainty is certainly true and that one of its parameters is set to zero and assuming I could regather my data in the same manner but randomly different ad infinitum.”
In the hands of a master, more significant p-values can be squeezed out of a set of data than donations Al Sharpton can secure by marching into an all-white corporation’s board room.
“Statistically significant” does not imply true nor useful nor even interesting. “Significance” is a fog which emanates from a computerized thurible, thick and pungent. It obscures and conceals. It woos and insinuates. It distracts. It is a mathematical sleight-of-hand, a trick. It takes the eye from the direct evidence at hand and refocuses it on the pyrotechnics of p-values. So delighted is the audience at seeing wee p-values that all memory of the point of a study vanishes.
Statistical significance is so powerful that it can prove both a hypothesis and its contrary simultaneously. One day it pronounces broccoli as the awful cause of splentic fever and tomorrow it is asserts unequivocally that broccoli is the only sane cure for the disease.
Both results will be accepted and believed, especially by those manning (and womanning!) bureaucracies and press rooms. Journalists won’t tell you about the deadly effect of either until 10 p.m. Government minions will latch gratefully on to anything “significant” as proof their budget (and therefore power) should be increased.
Time for statistical significance to be slain, its bones cremated, and its ashes scattered in secret. No trace should remain lest the infection re-spread. The only word of it should appear in Latin in tomes guarded by monks charged with collecting man’s (and woman’s!) intellectual follies.
Update Wuhahaha!
———————————————————————————
Thanks to Steve E for finding Ziliak’s piece.
1I didn’t think of this; I recall the name from the old usenet days.
Discover more from William M. Briggs
Subscribe to get the latest posts sent to your email.
I wanted to ask a really silly question to get my head around this. If I work in a brewery and am afraid the beer bottles are being underfilled by a machine. I could assume (null hypothesis) that the machine was pouring (on average) 1 pint into the bottles, get hold of a sample of say 20 bottle, work out the mean let’s say 0.94 pints and then calculate the probability of getting a sample mean of 0.94 given that the machine was pouring a (population) mean volume of 1 pint. If this probability was 0.03, I would say, there’s probably something wrong with the machine.
From my limited understanding of your and Ziliak’s articles, that’s it. I can’t say, well, it must be becasue the new guy working with it is useless.
It’s time to call the God particle by its proper name, as given in the following link – hidden so as to avoid your spam filter – oops.
http://www.independent.ie/world-news/scientist-wanted-to-call-it-the-goddamn-particle-because-it-was-so-elusive-26872413.html
I like your subtle link for those who posture.
Briggs,
Jaysus! You forgot again to type Wuhahaha after the third “die”… haha :D I love your blog.
Not a threshold, we can set many thresholds for the same p-value within an experiment (eg. 0.05 repeat experiment, 0.01 publish, 0.000001 run away with formula and sell to the Chinese…)
But I have a present for you:
A formula from Sellke, Bayarri, and Berger (2001) that can be intrepreted as as a lower bound on the conditional Type I error probability (or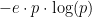 as a lower bound on the Bayes factor).
as a lower bound on the Bayes factor).
For low p-values its behavior is virtually linear which means that human inference based on probability or p-values would be equivalent to guess temperatures using Fahrenheit vs Celsius or Dollars vs Euros; if you take correct decisions with one there is no reason you take bad decisions with the other.
“Time for statistical significance to be slain, its bones cremated, and its ashes scattered in secret.”
OK. What do we use instead?
I fully concede both the limitations and the abuses of the principle, but in places where you simply can’t make a 100% direct causal connection between Factor A and Outcome B, I don’t see much else to fall back on, unless you happen to be an Ashar’ite philosopher who believes in full divine occasionalism.
My understanding about the discovery of the Higgs boson is that they found a very particular signal which is consistent with one very specific Higgs boson theory, and which is inconsistent with a number of other Higgs boson theories.
Which is not quite the same as a null hypothesis of having either one Higgs boson theory and a theory which says that there is no such thing as a Higgs boson at all, the null theory.
Haven t you over stated the ubiquity of 0.05% ?
Surely other p values apply based on “priors”. We KNOW prior to conducting a study that second hand smoke is evil. So we set p to 0.10
We know fears of fluoride in drinking water are paramour so p ought to be say 0.025 here.
We know from the deep sincerity of beautiful celebrities that MMR vaccines cause ADHD or other mental illnesses so the p value set to reject as insignificant any null to the contrary should be as high as 0.75?
I am almost surprised Bayesans don t get this …
Stephen J.,
How about a methodology that tests hypotheses against predictions instead of how well built the model are?
Oh, and for causal relationships, getting different data, say, by experimentation?
pouncer,
p-value is an answer to the wrong question. As Briggs (or rather Ziliak) pointed out (somewhat subtly), it’s a reversal of terms. See the quote “fallacy of the transposed conditional.†Using p-value for hypothesis testing is the equivalent of saying my model is good therefore my hypothesis is correct. Kinda like saying the total is correct so the charges on the bill must be OK.
Johnathan,
You’d think, brother, that after sampling 20 beers you wouldn’t care if they were short.
Meanwhile, if you saw 20 beers which were short, that’d be plenty of reason to suspect most were. Beyond that you need to start being very, exceedingly explicit about how you’d quantify your uncertainty. For a start (and the end), this.
“How about a methodology that tests hypotheses against predictions instead of how well built the model are? Oh, and for causal relationships, getting different data, say, by experimentation?”
Excellent recommendations, both; the problem occurs in those situations where the implementation costs, or the consequences, of waiting to validate predictions and conducting experiments are either impractical or unacceptable. (Imagine how much more robust and rigorous medical experimentation results could be if we went straight to human beings, and didn’t have to worry about whether the subjects died.)
You cannot operate in this world without having to make judgement calls about when correlation is strong enough to imply causation, and while statistical significance as most people actually use it may simply be an attempt to dress that decision up in mathematics to sound more certain, the judgement calls still have to be made, and the evidence for that judgement still has to be counted and weighed.
Pingback: Lancement de la revue “Statistique et société†| Polit’bistro : des politiques, du café
Excellent recommendations, both; the problem occurs in those situations where the implementation costs, or the consequences, of waiting to validate predictions and conducting experiments are either impractical or unacceptable.
If what you have is insufficient to establish causation or certainty of hypothesis then it seems your alternative is to wing it with a WAG. What dire situation requires action even in the face of uncertainty and is so dire that any action would be preferable to analyzing and waiting? I can think of situations but none of them involve statistical analysis: car out of control, building you are occupying on fire, for a couple. It most certainly doesn’t apply to desires to get a drug to market if that’s what you had in mind.
When all one has is a hammer…everything starts looking like a nail…
@ Jonathan Andrews: His brewery bottle filling example (1st post) raises a very fundamental factor overlooked & sidestepped routinely:
Given some statistical finding –what is the value of additional information? (something along the line of this, and more: http://www.wikihow.com/Calculate-the-Expected-Value-of-Sample-Information-%28EVSI%29 )
Related to that is, ‘What additional information really matters?’ “More of the same†to refine the finding already identified is usually not helpful.
J. Andrews broaches this: Go out & observe…maybe it’s a maintenance issue with the machine…maybe the new guy is doing something wrong (is he “useless” as speculated because he’s a dolt, or, was he provided poor training?).
The brewery example is representative of manufacturing & assembly line processes involving one or more machines & people; performance is studied and documented (‘baselined’) & when the statistics show a breach in allowable variability someone is sent out to find, and fix, whatever is causing the problem before it gets intolerable. When a possible problem is identified, the manager doesn’t want his uncertainty bounded, s/he wants the issue to go away ASAP—when it costs the least to resolve.
The error consistently presented is in thinking statistical analysis is the sole province to explore in addressing some problem…like any tool, it can be very good for what it does, but no tool does all that’s needed. This is the manager’s problem: Using consultants/subject matter experts (be they statisticians, lawyers, etc.) to the limit of their contributions—and no more! Knowing enough to be able to tell them they’ve contributed all they can, or better–all that’s needed, & to now go away & wait for the next assignment is crucial; left to their own devices, such experts [most anyway] would never finish, nor would they if left to their devices actually solve much of anything….
That’s the polite way of putting it.
the manager doesn’t want his uncertainty bounded, s/he wants …
One of those pronouns appears gratuitous.
FWIW: I prefer s/he/it.
“When a possible problem is identified, the manager doesn’t want his uncertainty bounded, s/he wants the issue to go away ASAP—when it costs the least to resolve.”
or why not say:
“When a possible problem is identified, the manager doesn’t want uncertainty bounded, rather for the issue to go away ASAP—when it costs the least to resolve.”
Personal pronouns are usually superfluous.
“If what you have is insufficient to establish causation or certainty of hypothesis then it seems your alternative is to wing it with a WAG.”
Granted; but you can learn enough to make some WAGs less WA than others, and if statistical significance as it’s currently practiced is no longer useful to that end, I’m wondering what would be.
“What dire situation requires action even in the face of uncertainty and is so dire that any action would be preferable to analyzing and waiting?”
Cancer treatments. Environmental damage. Car manufacturing faults. Likelihood of a terrorist attack with a WMD. A pilot deciding whether his live-saving transplant organ flight is worth the risk of taking off in a storm. Any situation where lives or similar high stakes are on the line but relevant factors can only be indirectly isolated or inferred. All of those require judgement calls that are neither certain nor wholly arbitrary, and it’s the process of reducing uncertainty that is ineluctable.
“womanning” – you jester Briggs. Now create a sentence with “manhole” in it.
So, if I’m following Mr Ziliak, the “fallacy of the transposed conditional” is the same as the “prosecutor’s fallacy”, right?
bluebob,
You are quite right about personal pronouns. The downsides are that it requires some skill in prose composition and more importantly you lose the opportunity to posture, which after all is what it is really about. I’m on a roll.
if statistical significance as it’s currently practiced is no longer useful to that end, I’m wondering what would be
Statistical significance never was useful to that end. It never indicates if the model is of any value. At best it indicates how well the model was constructed. A beautifully constructed car is useless (except as a marvel of art) if it doesn’t run. What’s needed is to quantify the uncertainty in the model’s predictions. Hard to do if you never test it with data not used in its construction.
DAV,
Re: “FWIW: I prefer s/he/it.”
‘It’ certainly seems most applicable to some I have to deal with.
A few remarks on Ziliak’s article:
That is false Mr. Ziliak. The Null Hypothesis simply assumed the current knowledge for the standard model and anything not abiding to it would have been detected whether it is the Higgs or not.
False again. If an economist is going to shame the thousands of top physicists at CERN maybe that economist should check what the CERN actually said about the discovery in the press conference:
Nature Magazine: Have you found the Higgs or what?
CERN:As a Scientist I have to say we have something, a Bosson, and we need to determine what kind of boson it is.
this answer can be check here: https://www.youtube.com/watch?feature=player_detailpage&v=AzX0dwbY4Yk#t=204s
As can be seen in the video above nobody did claim the Higgs was discovered.
Now, Mr. Ziliak, that makes you an ignorant because you ignore the content of the press conference at CERN, or a lier because you know but you are desperate to make a point, or maybe makes you a…[insert favorite hypothesis]
Riiight Mr. Ziliak, it was the p-value’s fault, surely the greed of the Japanese Government and Vioxx CEO had nothing to do with it… it was the evil p-value math that drove those honest politicians and CEO astray. We need to protect our politicians and large corporations CEOs from those damn p-values! Action Now!
Banishing this significance junk seems possible. Even the U.S. Supreme Court agrees.
By the way, there are also Judges that have banned the use of Bayes’ Theorem!. Just for you to know Mr. Ziliak.
http://www.analyticbridge.com/profiles/blogs/bayes-theorem-challenged-in-court-the-guardian
That’s right. Let’s trust lawyers when it comes to math and science, and screw those physicists at CERN… The hell with them.
Pingback: Bayes Is More Than Probably Right: An Answer To Senn; Part I | William M. Briggs
Would you also criticize confidence intervals along the same line?
Not really.
If I run a properly designed and replicated trial and discover that usage of a certain additive at no extra cost gives an improved result with a significnace of p=0.2, then I should make the decison to use that additive; after all, there is an 80% certainty the result did not occur out of chance alone.
However, if I am looking similarly at a very expensive additive, and get a similar result, I probably need to run a lot more and larger trials to see if I can attain a lower level of uncertainty (or certainty!) to justify the ongoing expenditure.
Likewise with the beer example described by Jonathan Andrews on 13 June 2013 at 8:21 am – an ideal use of p – a standard must be set for action – and it does not have to be p=0.01.
The problem lies not with p itself but with the blind adherence without contest to certain threshold levels.
ie – it should be; “Die, threshold value, die, die!!”
Curse the typos!
markx on 16 June 2013 at 7:49 pm said
“…The problem lies not with p itself but with the blind adherence without CONTEXT to certain threshold levels…”
ie – it should be; “Die, threshold value, die, die!!â€
OK, so to push this question further.
If confidence intervals are acceptable (but t-tests are not), then we could automatically convert a p-value statement into a confidence interval statement.
“The mean of population 1 was 1.35, while the mean of population 2 was 1.50. The means were different with p-value 0.01” now becomes
“The mean of population 2 is in the range [1.35, 1.65] with 99% confidence.”
Does this convert junk science into real science? It seems like Ziliak’s criticism will be (or ought to be) more far-reaching than simple semantics, yes?
Pingback: Cacotopian Brainwashing: Making Dystopias | Head Space
Pingback: Scientists Claim Zapping Brains with Magnets Can Treat Belief in God | saintandrewstwinflame
Pingback: Scientists Claim Zapping Brains with Magnets Can Treat Belief in God | Global Geopolitics
Pingback: Here’s Why That Study Claiming Religious Kids Are Less Altruistic Stinks | William M. Briggs
Pingback: Brits Psychologists Cry “BS!” Over Research Practices. Or, Die P-Value, Die Die Die – William M. Briggs
Pingback: Scientists Claim that Zapping Brains with Magnets Can Treat Belief in God | The Liberty Beacon