
Party trick for you. I’m thinking of a number between 1 and 4. Can you guess it?
Two? Nope. Three? Nope. And not one or four either.
I know what the number is, you don’t. That makes it, to you, truly random. To me, it’s completely known and as non-random as you can get. Here, then, is one instance of a truly random number.
The number, incidentally, was e, the base of the so-called natural logarithm. It’s a number that creeps in everywhere and is approximately equal to 2.718282, which is certainly between 1 and 4, but it’s exactly equal to:
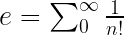
The sum all the way out to infinity means it’s going to take forever and a day, literally, to know each and every digit of e, but the only thing stopping me from this knowledge is laziness. If I set at it, I could make pretty good progress, though I’d always be infinitely far away from complete understanding.
Now I came across a curious and fun little book by Donald Knuth, everybody’s Great Uncle in computer science, called Things a Computer Scientist Rarely Talks About whose dust flap started with the words, “How does a computer scientist understand infinity? What can probability theory teach us about free will? Can mathematical notions be used to enhance one’s personal understanding of the Bible?” Intriguing, no?
Knuth, the creator of TeX and author of The Art of Computer Programming among many, many other things, is Lutheran and devout. He had the idea to “randomly” sample every book of the Bible at the chapter 3, verse 16 mark, and to investigate in depth what he found there. Boy, howdy, did he mean everything. No exegete was as thorough; in this very limited and curious sense, anyway. He wrote 3:16 to describe what he learned. Things is a series of lectures he gave in 1999 about the writing of 3:16 (a book about a book).
It was Knuth’s use of the word random that was of interest. He, an expert in so-called random algorithms, sometimes meant random as a synonym of uniform, other times for unbiased, and still others for unknown.
“I decided that one interesting way to choose a fairly random verse out of each book of the Bible would be to look at chapter 3, verse 16.” “It’s important that if you’re working with a random sample, you mustn’t right rig the data.” “True randomization clearly leads to a better sample than the result of a fixed deterministic choice…The other reason was that when you roll dice there’s a temptation to cheat.” “If I were an astronomer, I would love to look at random points in the sky.” “…I thin I would base it somehow on the digits of pi (π), because π has now been calculated to billions of digits and they seem to be quite random.”
Are they? Like e, π is one of those numbers that crop up in unexpected places. But what can Knuth mean by “quite random”? What can a degrees of randomness mean? In principle, and using this formula we can calculate every single digit of π:
![\pi = \sum_{k = 0}^{\infty}\left[ \frac{1}{16^k} \left( \frac{4}{8k + 1} - \frac{2}{8k + 4} - \frac{1}{8k + 5} - \frac{1}{8k + 6} \right) \right]](https://s0.wp.com/latex.php?latex=%5Cpi+%3D+%5Csum_%7Bk+%3D+0%7D%5E%7B%5Cinfty%7D%5Cleft%5B+%5Cfrac%7B1%7D%7B16%5Ek%7D+%5Cleft%28+%5Cfrac%7B4%7D%7B8k+%2B+1%7D+-+%5Cfrac%7B2%7D%7B8k+%2B+4%7D+-+%5Cfrac%7B1%7D%7B8k+%2B+5%7D+-+%5Cfrac%7B1%7D%7B8k+%2B+6%7D+%5Cright%29+%5Cright%5D+&bg=ffffff&fg=000&s=3&c=20201002)
The remarkable thing about this equation is that we can figure the n-th digit of π without having to compute any digit which came before. All it takes is time, just like in calculating the digits of e.
Since we have a formula, we cannot say that the digits of π are unknown or unpredictable. There they all are: laid bare in a simple equation. I mean, it would be incorrect to say that the digits are “random” except in the sense that before we calculate them, we don’t know them. They are perfectly predictable, though it will take infinite time to get to them all.
Here Knuth seems to mean, as many mean, random as a synonym for transcendental. Loosely, a transcendental number is one which goes on forever not repeating exactly its digits, like e or π; mathematicians say these numbers aren’t algebraic, meaning that they cannot be explicitly and completely solved for. But it does not mean, as we have seen, that formulas for them do not exist. Clearly some formulas do exist.
As in coin flips, we might try to harvest “random” numbers from nature, but here random is a synonym for unpredictable by me because some thing or things caused these outcomes. And this holds for quantum mechanical outcomes, where some thing or things still causes the events, but (in some instances) we are barred from discovering what.
We’re full circle. The only definition of random that sticks is unknown.
I have heard that if the Riemann Hypothesis were to be solved then the evidence for the existence fo randomness would be undermined to a very great extent. Is this your understanding? I concurr with the statement that “there is no such thing as randomness, – that randomness is an illusion that beings that are not omniscient are subject to!
JJM 😉
If Quantum Theory is wrong about something, and another theory is right, you should be able to use the other theory to pinpoint the error in Quantum Theory. Repair the error, and Quantum Theory will still be able to predict correctly what it predicts now, and it will in addition be able to predict the things that are now thought te be random.
Sander,
You lost me, brother.
Suggestion to all: try writing your comment without using the word “random.” We have already seen that it has many shades of meaning. To avoid equivocation, leave it out—unless you’re demonstrating a definition.
Jules,
Something like that is my understanding, yes. But see the suggestion.
I try to avoid using “random” as an adjective anymore, as in “random sample”.
I’ve found that “representative sample” is both more descriptive and easier to explain.
BTW, I think I get Knuth’s joke in 3:16 being “random”.
Matt, interesting post, well done.
FYI, in WordPress ou can make the equations larger by adding
&s=2
or
&s=3
before the end of the latex. From memory you need the space before the ampersand.
All the best,
w.
Willis,
Thanks! I had no idea. Much better!
For fun I typed in define random to Google.
made, done, happening, or chosen without method or conscious decision
Which is funny when you hear about random number generation – there’s always a method. Drawing straws, shuffling cards, using an algorithm, picking red and black balls from a box. Which leaves the conscious decision (or cause)… and its turtles all the way down to the first cause, so the definition seems to not define anything in reality.
Could it better be stated and generalize that an event or result described as truly random simply means that the outcome was unknowable to any physical observer, no matter what measurement methods are used? Quantum indeterminacy comes to mind, perhaps, and also the random reason my wife is angry at me today.
A less strong form reverts back to simply unknown to the current set of observers…
My understanding was that the only true way to get a random number was to use the disintegration of a radioactive atom … there’s no way to predict it, and it’s not the result of a calculation. True? Urban(e) legend?
The world wonders …
w.
Briggs:
If I were to provide you with a set of 20 allegedly random digits, could you not use your Bayesian methods to determine the likelihood that they were not generated by a truly random process?
That is true about the radioactive decay, Willis, and the method has been used. Aren’t you on vacation?
Briggs, with respect to the QM: “And this holds for quantum mechanical outcomes, where some thing or things still causes the events, but (in some instances) we are barred from discovering what.”
This is not the way I would phrase it. The wave function collapses into one or another final state. The collapse is caused (by observation?) but is the “choice” of state caused or is it truly random? It is certainly non-local.
Very well, QT states that certain things cannot be predicted exactly. Like the time a certain radioactive decay will happen. If there’s a cause for everything, then QT is wrong. Where?
bTW, some googling for Bell’s Theorem turned up a concept, superdeterminism, that make quantum effects completely predictable. At the cost of free will and lots of other things.
Sander,
We see that Briggs is secretly a Calvinist. 😉
If you need a bunch of random digits, I suggest that you pick up a copy of A Million Random Digits with 100,000 Normal Deviates.
The reviews are rave, though there are some that express disappointment: “Such a terrific reference work! But with so many terrific random digits, it’s a shame they didn’t sort them, to make it easier to find the one you’re looking for.”
Actually, I was going to use row 3, column 16 of my CRC “Standard Mathematical Tables” 25th edition.
Dr. Briggs, there is also another kind of number, different from the likes of pi and e transcendentals, for which no construction algorithm can be found. For such numbers knowing ANY arbitrary number of digits is useless in predicting or finding any other digit, in this sense they are random.
The case of Q. Mechanics and Classical mechanics should also be looked more closely as they entail different kinds of randomness. In Classical Mechanics the ignorance about initial conditions leads to probabilistic results, the example of a flipped coin is perfect, it is only because we don’t know the exact initial conditions that we quantify our uncertainty about heads and tails. In the case of quantum mechanics you can think that a system with a Complete list of initial properties may have different possible future properties. This system is analogous tho the algorithmic random numbers I talked about earlier.
p.s: All this does not imply randomness causes anything.
@Scotian
😀
Hello all–I can’t add much to the discussion other than give a reference to “The Unknowable” by Gregory Chaitin, in which there is a chapter on deciding whether computer generated number strings are genuinely a string of random numbers by using Algorithmic Information Theory (AIT)… please don’t ask me to explain further.
Mike B. Yes, 3:16 is definitely more “random” than 3:14 would be!
But actually there *is* a difference between random and representative in that the former refers to how the sample was selected (ie involving at least one step in which the experimenter has no way of predicting the exact outcome) and the latter refers rather to the use to which the sample will be put (ie as a source of presumed information about a population).
The University of Geneva is giving away random numbers if you want some.
http://www.randomnumbers.info/
I avoid the term “random sample” mainly because I tired of dealing with nit-pickers who insisted on a literal interpretation of “random”, as in “are you using a computer to generate random numbers? You know those really aren’t random”. “Representative sample” gets you past that, because as you state, it represents your objective, not necessarily your method. Sometimes haphazard samples work fine, sometimes you employ pseudo-random numbers, sometimes you block, etc.
I am puzzled by ” …quantum mechanical outcomes, where some thing or things still causes the events…” How can you be sure of this?
Or before that, perhaps I should be asking what exactly do you mean when you talk of one thing or event “causing” another? (Preferably in brief words of your own rather than by reference to some other source)
Sorry, in case it’s not obvious my previous comment was intended for Briggs op rather than the one from Mike B that came just before it.
Mike B, Yes, fair enough – at least if you don’t want to use the data to compute a (cough! cough!) p-value. (Or for that matter to make a Bayesian adjustment of your probability estimates).
@Alan Cooper
“I am puzzled by †…quantum mechanical outcomes, where some thing or things still causes the events…†How can you be sure of this?”
I’m not sure what the question means. The evolution of the state function is deterministic.
The projection operator corresponding to measurement picks out one component of that state function. The probability of a particular component being measured is given by the square of the absolute value of the coefficient of the component in the state function.
This isn’t randomness.
PS–I don’t believe there are causal relations in this theoretical description; it’s merely our attempt to describe what’s happening in reality.
And there are no causal relations in Maxwell’s equations, in the Principle of Least Action, or… any other theoretical formulation.
“This isn’t randomness.”
It’ll do until a better description comes along and it fits Briggs’ definition.
“And there are no causal relations in Maxwell’s equations”.
There are when I teach them.
Scotian, I do believe (and we probably differ on this) that causal relations are for “real” events, not equations. What is the causal agent in divergence of B =0??? Or in the Ampere Circuit Law? These are our attempts to describe what occurs, and the equations are descriptive, not prescriptive.
And it fits Briggs definition….
I’m not sure I agree with Briggs definition.
Here’s a web site (with much of what’s in Chaitin’s book) that gives several definitions of randomness that can be tested operationally (unlike the statement that quantum mechanics is random).
https://www.cs.auckland.ac.nz/~chaitin/ait8.html
If there is a probability associated with a possible measurement value, I don’t consider that as a random process, even though several possible events may occur.
Thus I don’t consider radioactive disintegration as a random process, since you have a distribution function for the time interval in which a disintegration might occur.
When I was taught statistics the definition of a random sample was that any member of the sample set was equally likely to be selected. If you have a string of digits, then the considerations given in the linked paper would tell you if the string is random, i.e. whether the algorithm giving the string is compressible to less information than given in the string. If you have a set of numbers corresponding to radioactive disintegration times, that information can be compressed into an exponential distribution function algorithm.
Kurland,
Ampere’s circuital law shows that a moving charge (current) causes a magnetic field as does the Biot-Savart law in another form.
“When I was taught statistics the definition of a random sample was that any member of the sample set was equally likely to be selected.”
It is easy to find a QM system of only two outcomes of equal probibility.
“Thus I don’t consider radioactive disintegration as a random process, since you have a distribution function for the time interval in which a disintegration might occur.”
The probability of decay of any given radioactive nucleus is independent of time. It thus fits your definition of random. Yes I know what you are saying but it is no different than throwing dice (hypothetically random) repeatedly every minute and finding the half life of getting snake eyes. There is no memory in the system.
” The only true way to get a random number was to use the disintegration of a radioactive atom.”
I hate this… there are lots of physical processes where, if a person new all of the data about the initial conditions they should be able to know the outcome. But the outcome is so sensitive to small errors in the estimations of initial conditions that the outcome is definitely not predictable.
I had no idea that there was a series the converged to pi so quickly.
Matt, would have liked you to have included cellular automata re ‘random’. Incontrovertibly deterministic, yet knowledge of state is ‘incompressible’ even in principle.
Given Pr(A) | E, I would abstract many of the comments here as ‘random’ meaning, ‘a procedure that produces a certain kind of E’. From the comments here, in practice, very intelligent people, including working scientists and engineers, don’t appear to care much about ‘random’ in itself, and we get confused by niceties about its definition. In practice, we don’t really care whether ‘random’ means ‘causal’ or what not; we just want that certain kind of E.
That is, we want ‘random’ not to mean ‘unpredictable’ or ‘unknown’ or ANYTHING per se, but to have ‘random’ have a social meaning (p<.05, anyone?) that somehow allows you (without risking social criticism) to 'guarantee' the kind of E that you want.
Of course, as you've written so often, if you want a certain kind of E, go out and get it yourself. But that wouldn't be 'random' by anybody's definition, which scares people off, by subjecting one to criticism that one's E wasn't properly 'representative'.
You have an excellent treatment here; but it's an extremely difficult subject, made more difficult by how much we all seem to want 'random' to mean 'productive of a certain kind of E'.
“The probability of decay of any given radioactive nucleus is independent of time. It thus fits your definition of random. Yes I know what you are saying but it is no different than throwing dice (hypothetically random) repeatedly every minute and finding the half life of getting snake eyes. There is no memory in the system.”
Your definition of random is that of the set of possible outcomes, each outcome is equally probable. So your example of throwing dice would fit that.
But radioactive disintegration wouldn’t fit that. Suppose you measure disintegration of a radioactive sample with a half-life of 1 minute over a 10 minute period. Your radioactive counts will not occur randomly in that 10 minute period; if you measure a radioactive sample with a half-life of 1 million years over a 10 minute period, the disintegration rate would appear to occur randomly, but that is a special case of how the measurement is carried out and what kind of sample you have. So it is not a universal that radioactive disintegration occurs randomly.
And with respect to quantum mechanics, having two possible outcomes with equal probabilities (as with measuring a spin component of spin 1/2 systems) may also, in the sense of having equal probabilities for any possible outcome be a random process. But that is a special physical situation, not applicable for quantum mechanics in general. You could also consider the measurement of position of a free particle (infinite box) or the analogous measurements of one canonical variable with the corresponding canonical variable fixed.
With respect to Maxwell equations, with curl E = – partial derivative of B with respect to t, is it the time change of B that causes the spatial distribution of E or the spatial distribution of E that causes B to change with time? And your description of current causing a magnetic field is the same–does the current “cause” the magnetic field or does the magnetic field cause the charge to move? You infer causal relations where there is only an association of phenomena; you look to equations as prescriptive and I look to them as descriptive. It is in the measurements that
we find reality, not the equations.
Mathematically, the definitions give for randomness are specific and operational. Others are hand-waving.
Scotian, here’s a question for you … suppose you have a charge moving with a uniform velocity v; and suppose you also move with the same velocity v… will you see a magnetic field? and can the moving charge therefore be said to cause a magnetic field? Or is it only if the charge moves with respect to you, the observer that there is a magnetic field…. hmmm….
@Bob Kurland
If you have several radioactive atoms, in separate chambers, each chamber having their own geiger counter, then you cannot predict at which time a specific arom will decay.
You know and can measure that after the half life time of that particular atom about half of them will have decayed. You cannot predict which ones that will be.
@Bob Kurland “PS–I don’t believe there are causal relations in this theoretical description; it’s merely our attempt to describe what’s happening in reality.”
Then perhaps (if I understand you correctly) we are in agreement.
The point of my question to Briggs was to ask why he thinks that there *must* be causes behind everything in the sense of his claim that ” some thing or things still causes the events”
@Bob Kurland, Re your 12:08AM post: Believe it or not, there is a YouTube video that answers your exact question:
http://www.youtube.com/watch?v=1TKSfAkWWN0
@alan cooper,
alan, I’m not sure you have understood me. I don’t deny there are causal relations in real events (I’m not a big fan of Hume). I’m saying there are no causal relations in the equations that describe events…. The equations are math. There’s no causal relation in x+2=4 nor, as I tried to point out above, in Maxwell’s equations, the Maxwell-Boltzmann distribution law, etc…
@Sander van der Waal
“If you have several radioactive atoms, in separate chambers, each chamber having their own geiger counter, then you cannot predict at which time a specific arom will decay.
You know and can measure that after the half life time of that particular atom about half of them will have decayed. You cannot predict which ones that will be.”
You’re quite correct in your example, but in the laboratory radioactive decay is not measured by looking at individual separated atoms. Radioactive decay is an example of a Poisson process. For a hypothetical individual nucleus, the decay is admittedly random. If you were only to look at one atom you wouldn’t learn much. You measure what’s happening with a sample and for that sample the Poisson process gives a Poisson distribution for the number of radioactive counts per unit time, and an exponential distribution for the amount decayed with total time.
In the same way, if you look at the double slit experiment and the passage of a photon, you’re not going to be able to say beforehand where the screen will scintillate. But if you get enough particles going through, you’ll be able to match the pattern, so it will not be a random process.
Again, I urge people to look at Chaitin’s definition of randomness and information.
@Milton Hathaway
My question was rhetorical. The Lorentz-transformation shows that if you move with the same velocity v (direction and speed) as the moving charge you will not see a magnetic field.
By the way either I don’t understand the video or it’s not correct. If you move an unmagnetized piece of metal you will not generate a magnetic field. If you move a magnetized piece of material you will generate an electric field (as in a dynamo or generator).
Bob Kurland asks, “… suppose you have a charge moving with a uniform velocity v; and suppose you also move with the same velocity v… will you see a magnetic field? … hmmm …”
My answer: Not unless you are another electron. And if you ARE an electron moving parallel to the other one, you will feel the same attractive force towards it as it feels towards you. If you drew an arrow to represent that force, as a vector, you would have a tangent at one point on one of the infinite number of ‘lines of force’ which you might eventually construct to represent the ‘field of influence’ of the little traveler.
A magnetic field cannot be said to ‘exist’, in the same sense that the electron exists. It cannot be seen at any time. The ‘field’ is a mathematical (or graphical) representation of a selection of possible observations concerning the behaviour of another charged particle – or of a small magnet (containing circulating electrons) – in the presence of the ‘field generator’. It is a graphical representation of ‘an effect’ observed. It is not an object; not even an event. A map is not the territory it purports to describe.
@Bob Kurland
I’ve seen his definition.
My aim with the atoms in their separate boxes is to show the three things you can measure about radioactive decay. QT does not predict the results of two of the experiments, and it predicts the third one, in the form of a specific distribution with a specific variance. We cannot predict per atom when it decays. But we can predict the resulting distribution. So the process that decides when a given atom decays is random. The resulting distribution of decay times for all atoms is not random.
Sander, I guess we agree…sort of…
@oz wizard..
“.A magnetic field cannot be said to ‘exist’, in the same sense that the electron exists. It cannot be seen at any time. The ‘field’ is a mathematical (or graphical) representation of a selection of possible observations concerning the behaviour of another charged particle – or of a small magnet (containing circulating electrons) – in the presence of the ‘field generator’. It is a graphical representation of ‘an effect’ observed. It is not an object; not even an event. A map is not the territory it purports to describe.”
Good point!
This can’t be right. If the process is random individually then how could a pattern emerge in the aggregrate beyond a uniform distribution?
Part of the problem is that a random sample can be drawn from *any* probability density function — including the Dirac delta function, in which case every random drawing will produce the same number. Most people, though, really do think of random numbers being drawn from a uniform pdf. This creeps into things like the argument for fine tuning of the fundamental physical constants. For more details, see this.
Obviously the digits of \pi can only be a pseudo-random sequence of numbers, but if they pass our statistical tests for randomness, that is still an interesting fact.
Kurland,
“So your example of throwing dice would fit that. But radioactive disintegration wouldn’t fit that.”
They are not so different. Imagine that you have an ensemble of paired dice that you throw together and whenever a pair shows snake eyes they are removed from the next throw. The system has an half life (36 minutes?) and in the limit will exhibit exponential decay.
“And your description of current causing a magnetic field is the same–does the current “cause†the magnetic field or does the magnetic field cause the charge to move?”
A uniform current in a wire will produce a magneto-static field but applying such a field will not produce a current let alone cause the wire (charge) to spring into being.
“With respect to Maxwell equations, with curl E = – partial derivative of B with respect to t, is it the time change of B that causes the spatial distribution of E or the spatial distribution of E that causes B to change with time?”
Similar problem and in any case there is a different equation for the change in E producing a B-field (curl of B etc). Because they are causal we can combine them to produce the self propagating wave equation.
“Or is it only if the charge moves with respect to you, the observer that there is a magnetic field…”
I suppose the answer to this question depends on whether you think that special relativity is a real phenomenon or just the appearance of one. Does the moving rod really shrink?
This can’t be right. If the process is random individually then how could a pattern emerge in the aggregrate beyond a uniform distribution?
Try rolling a pair of dice and observe the pair sum value distributions. 5 will be more often than 2.
This actually proves my point. We know that an individual roll of a pair of dice has a 1/36 chance of summing 2 and a 4/36 chance of summing 5. This can be explained for each individual roll and in the aggregate. In other words, it is explicable at both the individual and aggregate level. If the roll were truly random it would be inexplicable at both levels.
Given the all-important role randomness is supposed to play in cosmology and evolution, I find it ironic that nobody can agree what it actually means.
In these areas randomness is invoked as a positive explanatory principle – but randomness, like a hole, is not a positive thing, but rather the absence of something. It is a metaphysically negative, not positive. As such it simply cannot do the pulling it is called on to perform.
And yet we find the appeal to randomness time and again. It is practically the fetish object of the advocate of scientism.
DS Thorne, kindlefrenzy.weebly.com
Scotian, I guess I really haven’t made my point, which is there are no causal relations in the equations, only in the events they attempt to describe. To give another example, when an electron falls from an excited orbit and emits radiation, the electron falling to the lower energy level can be said to be the “cause” of the emitted radiation. But in the equation describing that delta E = h f (frequency) there is no causal link.
Kurland,
“which is there are no causal relations in the equations, only in the events they attempt to describe.”
That is what you are saying now. This is what you originally said:
“And there are no causal relations in Maxwell’s equations, in the Principle of Least Action, or… any other theoretical formulation.”
I agree that the symbols used in the equations do not have causal import but physics equations and laws are more than the symbols used to express them. What you are saying now is banal.
Scotian said
“I agree that the symbols used in the equations do not have causal import but physics equations and laws are more than the symbols used to express them. What you are saying now is banal.”
definition (Oxford): “So lacking in originality as to be obvious and boring:”
thanks for the kind words Scotian but that doesn’t deny the truth of my statement. go argue with Bas van Fraassen, Nancy Cartwright, … since I’m not being original.
and thank you for the enlightening discussion…
Kurland,
“that doesn’t deny the truth of my statement”
It denies the truth of your original statement which I originally responded to, and since the examples you gave were incorrect they reinforced my interpretation. I knew that you would react to my use of the word “banal” but I couldn’t think of any other method to get my point across which is that I felt there had to be something more behind your statements. I still think that there is.
Scotian, The examples weren’t incorrect.
and as far as repeating goes, when I’ve taught I’ve found that when the point isn’t taken or the student doesn’t repetition helps.
And if you want to see what is “behind my statements”
read
http://rationalcatholic.blogspot.com/2014/06/confessions-of-science-agnostic.html
and the references therin: Jaki, Cartwright (it’s on the web) and van Fraassen.
If I wanted a random number I would take a broadband noise diode, similar to that used in testing noise figures of radio receivers or RF amplifiers, run the output into a comparator to produce logic compatible signals, and run the comparator output into a counter of the length of the number I needed.
Whenever I needed a random number, I would read the counter.
Does anyone know why this WOULDN’T produce a truly random number? It seems trivially easy, and I cant think of any way to predict ‘the next number’. There is probably a catch, but I’m not smart enough to figure it out by myself.
Bob (Ludwick)… Interesting idea. I think the catch might be that you’re bandwidth limited…i.e. you don’t have an infinite span in frequency.. that’s my guess, so the numbers you get wouldn’t span the whole range of possible numbers. … in other words it might be a a finite (semi-) uniform distribution and possibly, because of bandwidth edge effects, not quite uniform…
@ Bob Kurland
It would certainly span the whole range of possible numbers with (n) digits, where n is the number of digits in the random numbers of interest. I. e, the number of digits in my counter. If, for example, I needed a 6 digit random number, it would simply count from 000000 through 999999, at a rate determined by the output of the noise comparator and would be at one of those million states when I needed a random number. As far as I know, there is no way of knowing, or predicting, the state of the counter at any time. Nor is it likely to be synchronous with the loop time of the program that requires the random number. Is it??
Again, it is so simple that there there has GOT to be something wrong with it, but I don’t know what.
@Bobs (K&L): I know virtually nothing about electronics so this may be a silly question, but is it obvious that there is no bias in the signal distribution from the noise generator? It seems to me that your numbers might be random in some sense but not necessarily uniformly distributed (eg they may be Poisson or Exponential or whatever). So far as I know there is no useful sense in the word “random” without specifying the expected probability distribution.
@Bob Kurland, I know you understand the physics but there may have been a misprint in your response to Milton Hathaway. Did you mean “uncharged” rather than “unmagnetized” when you said “If you move an unmagnetized piece of metal you will not generate a magnetic field. “?
As far as the video goes, I thought it was substantially correct, so maybe we are making different interpretations of something the presenter said.
On the issue of cause, I think the misunderstanding may be going both ways.
I agree with what I think you mean by “there are no causal relations in the equations that describe events” and I don’t deny there are sometimes relations between real events that can reasonably be called “causal”. I’m just *asking* how Briggs (and maybe you?) can claim to be *sure* that every event has a well-defined cause.
P.S. Going back to the video, although I didn’t see it as wrong I think it was addressing a somewhat different question from the one you asked, so I guess it could be considered wrong if it had been created as an answer to *your* rhetorical question (about the magnetic field due to a moving charged object rather than to a current in a stationary neutral wire).
yeah alan, it was late at night, and sometimes the distances between synapses for this old guy seem to get further apart. i did mean uncharged (total net charge 0). My original point was that if you are stationary with respect to a moving charge you can measure an engendered magnetic field. If you move at the same velocity as the charge there will be no magnetic field to measure. This is verified by a Lorentz transformation of the Maxwell equations. Which is why I claim there are not causal relations in the equations : the symbol v does not cause the symbol B. And the other example, an electron dropping to a lower energy level and emitting radiation: delta E = h f. delta E does not cause f.
@Bob Ludwick, since you asked, yes, a noise diode (we used a lightly biased Zener diode) fed into a comparator will generate what we called a “random” binary sequence. And yes, there’s a catch – since it is an analog circuit, the output will invariably be contaminated with things like 50/60Hz mains hum, cross-coupled clock edges, RF interference, microphonics, drift, etc.
So we switched to using what we called a “PRBS” (pseudo-random binary sequence) generator, which produced a “random” binary sequence, using a long digital shift register feeding back various delay taps via XOR gates, back to the input. The selection of shift register length and choice of taps were straight out of Knuth, I believe (TAOCP, Volume 2, Chapter 3); the repetition period of the PRBS sequence was chosen to be very long (years).
But then a customer complained about a spurious ripple in the frequency response when the PRBS-based noise source was used to excite certain non-linear systems. The ripple was closely related to the spacing of the taps; you could make it less noticeable by choosing different taps, but you couldn’t get rid of it completely.
So we ended up using both a noise-diode source and a PRBS source, and XOR’ed the two together. Again, this was something straight out of Knuth, I believe – some sort of theorem about random noise sources, that if you multiply two noise sources together, the resultant noise source is at least as random as either of the two original sources. In this case, each of the two input noise sources nicely compensated for a weakness in the other.
At this point you might be wondering “why binary?” Well, this was a very long time ago, and it would have taken a whole printed circuit board full of parts to perform a single digital multiplication in real time. But it was easy to do a weighted sum of sequential binary values by adding adjacent outputs of the shift register using resistors. A poor man’s FIR digital filter, if you will.
@Bob Ludwick, @Milton Hathaway – The diode random number generator has long been used as a source of “random” numbers for cryptography. It has also long been studied by cryptographers as it’s failure to be “perfectly random” provides leverage for cryptanalysis.
If you build one, and superficially tune it, it will look pretty random. If you use it for an important one-time cipher, serious cryptographers will break it pretty quickly. It takes a lot more trickery, some classified [disclaimer: I know this is true but I don’t know the classified info itself], to make a better, but still not completely random generator.
Which brings to mind the off-topic tale of the Venona Transcripts. This was a mostly successful decades long effort by the NSA (and ASA) to break a 1940’s and (I think) 1950’s era Soviet code used by spies in the US. Venona used a one-time code… theoretically unbreakable. However, the Soviet bureaucracy assigned the job of producing the one-time pads fell prey to the Stalinist practice of constantly having its required productivity increased. It ultimately re-issued some of the one-time sequences to meet the goals. This relatively small mistake was enough for the code breakers.
If you build one, and superficially tune it, it will look pretty random. If you use it for an important one-time cipher, serious cryptographers will break it pretty quickly.
They may be able to extract *some* information about the messages, but it’s only useful in fairly specialized circumstances, when they already know a lot.
It takes a lot more trickery, some classified [disclaimer: I know this is true but I don’t know the classified info itself], to make a better, but still not completely random generator.
It may have been classified once, but we’ve now got the Impagliazzo-Levin-Luby ‘Leftover Hash Lemma’ which does the job. The main issue is estimating how much redundancy there actually is in the source.