
We’ve done regression a hundred times, but it isn’t sticking. That means my explanations are failing. Let me try again.
Everybody knows normal distributions, i.e. bell-shaped curves: in shorthand N(m,s), where the “m” is the central parameter, which describes where the peak of the bell is centered, and “s” is the spread parameter, which describes the width of the bell. Both parameters are needed to draw the curve. The one at the top of the post has m = 3 and s = 1.
Suppose we wanted to characterize our uncertainty in the GPA of a Harvard student. Well, that’s 4.0, because the little darlings enrolled there deserve nothing less. So let’s pick another school. Bowling Green. We might, for no good reason and many bad ones, use a normal distribution to quantify this uncertainty. Hey. Everybody else does it. Why not us?
That means the normal distribution which characterizes our uncertainty in the GPA of a Bowling Green student (singular) has some m and some s. Both are needed. Right?
Regression is the formula:
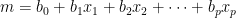
Do you see? We model the m; we say the m is a function of various things, the x’s. Maybe one of the x’s is age, another is sex, a third is income, a fourth is BMI, a fifth is height, a sixth is presence of some gene, a seventh is whether the individual is a science major, an eighth is whether the individual is Caucasian, a ninth is high school GPA, a tenth is SAT score, an eleventh, a twelfth, thirteenth, and on and on and so on some more. You’d never make it as a sociologist unless you can think of at least two dozen entries.
Wee p-values are invoked, via mathematical incantation, to decide which of the x’s to keep. But whichever x’s are there, the following interpretation holds. Each combination of x’s implies a different value of m. Each combination of x’s puts the peak of the bell curve at a new value. The spread is always the same. It does not matter what any x equals, s gives the same spread to everything. Where by “everything”, I mean everything.
Sharp readers will have noticed that there is not word one about causality. Because why? Because regression is silent on this important subject. Regression only does what we asked it to do: to characterize our uncertainty in some observable (here GPA) using a normal distribution with a central parameter given as a function of some x’s.
Regression does not say anything direct about the observable. It does not say what the value of the observable will equal given some combination of x’s. Regression would be a causal model if that were true. And it only indirectly says anything about the probability the observable will take any value given the x’s—but that’s because of screwy limitations of normal distributions and classical procedures, which we’ll skip here.
Consider that the x which represents whether the individual is Caucasian increases m. That does not therefore mean whites have higher GPAs than non-whites. No no no no no. No. It says, very indirectly and after manipulation most people forget to or don’t do, that given this model and these x’s, the probability whites have higher GPAs than non-whites is greater than 50%. (The exact probability can be calculated.)
Are these the right x’s? Maybe. What do you mean by “right”? Remember: regression doesn’t say what causes the observable, only which x’s change our understanding of the uncertainty of the observable. So if by “right” you mean just those x’s which cause the observable, then almost certainly we don’t. Consider our example.
Race can not cause GPA to take any value. How could it? You might try claiming that “racism” is what accounts for whites to have higher m’s, but you do so with no direct proof. All you can see is that, with the combination of x’s in your model of m, whites have a positive contribution to m. To say that racism is the cause is to eschew all others—an act of will. Why? Because there are an infinite number of possible causes of why whites have, in the presence of these x’s, a positive combination. Plus, this is just one model, the normal, out of many we could have chosen.
I emphasize “the presence of these x’s”, because in the presence of other x’s, the contribution of Caucasian, or any other variable, might switch signs, or might even evince a p-value not wee enough to keep it in the model. The only way to know what these changes would be is to check and see. But since we work with what we have, we’re stuck with the x’s on hand.
Yet it is difficult—impossible?—to find any “researcher” not abusing the definition of regression, and who doesn’t imply that his x’s are true causes, who doesn’t say the changes in m are changes in the observable.
What bad teachers we statisticians are.
I wonder if it might help, in the pedagogy, to switch from calling regressions models (in a general sense) to calling them “data models”. In other words, somehow force the reader and the student to recall at every possible moment that the model is only a model of data, and not of reality.
Maybe we could even call them “data uncertainty models” to further specify that all we are doing is looking for a relationship in a model that reduces our uncertainty of y given x. We could abbreviate them DUM, and then researchers would be forced to write things like “in this paper we use DUM ideas”. That could be fun.
Part of the problem is that “statisticians” aren’t doing the teaching, but rather psychologists, social scientists, etc.–that is, those with “practical experience” in submitting data to SAS or SPSS.
James,
I herewith accept and will adopt your most excellent suggestion of DUM ideas.
James –
I like it.
In graduate school, my son studied mathematical statistics from a book that was 1267 pages long. The authors of this immense tome, both of them professors of business administration, evidently knew of no better way of extracting a model from the evidence than – you guessed it- regression analysis. Thus, my son left his twelve years of lower education and six years of higher education lacking training in the essential skill of how, in logic, he could generalize.
Briggs and Will,
I’m glad you like my DUM idea.
Briggs:
I wasn’t that sharp, but I am learning. I need a post-it note on my laptop that says, “Regression is silent on causality.” It’s less shopworn than the meme about correlation and the same — though, I expect it has just as much potential for abuse as a zinger intended to cut down an argument one doesn’t like with one fell swoop.
I well remember the great liberal hue and cry of 1994 over Herrnstein & Murray’s treatise on bell curves, intelligence and American class structure. Never read it, it was one of those things I figured out was likely bunk just by listening to the debates.
I have no proof, but anecdotal personal experience leads me to conclude that there are causal cultural and environmental factors which have just enough correlation with race to generate wee pee values when race is used as a convenient proxy to infer something about the actual causal factors.
Ascribing predictive power to skin color in statistical terms is just a sciency way to call a spade a spade while possibly being able to evade sonars tuned for detecting politically incorrect language. Which, to use a perfectly legitimate medical term, is retarded.
Oh dear, we agree!
And with computers, we can offer ourselves many choices, giving us a cornucopia of buffet-style dishes to gorge upon according to what we find tasty and palatable. Something that has good mouth feel as they say in the food biz. A good wine is one that I like, right?
There are at least three basic ways that we get stuck with such exes:
1) They happened in the past and cannot be reobserved.
2) We don’t have time/money to gather more of them.
3) We don’t want to gather more because we like the ones we have.
There is a fourth way: we simply chose the wrong partner to marry.
Speaking from the perspective of a brain-damaged frequentist who forgot most of what I almost learned after aceing the final exam: it’s difficult stuff to understand.
I sort of remember understanding way back then that rejecting a null hypothesis does not “prove” it is false. And the converse: accepting a null hypotheis does not “prove” that it is true. Later personal observation proves that “proof” is wildly misused in all sorts of inappropriate contexts.
The unanswered question here is: how does an ethical, dispassionate, objective, unbiased researcher choose “good” exes? If no such exes currently exist, how does such an investigator go about gathering exes that haven’t already been observed?
Gates,
“Oh dear, we agree!”
I could be wrong, but the way that I read Briggs is that you do not agree. That Briggs is a subtle fellow and to say that regression does not imply causation is not to say that causes do not exist.
Scotian: I agree with him, exactly, on the point I was immediately addressing, and in fact, most of his entire piece today. Yes, Briggs is a subtle cagey fellow, just my kind of guy really. However, all my agreeablness was just the lead in to asking about what he left out, namely my questions in the final graf of my response.
Briggs,
Seems to me what you’ve described is a finding a solution resulting in a set of betas (not necessarily unique) that yield the lowest error. However, I don’t see where the use of the normal distribution necessarily follows. A conjugate gradient minimizer would also find the set(s) of betas. The only criterion is minimum error with respect to Y.
That is, as long as the variable are ordinal. Using nominal variables (such as race or sex) can be dicey in a regression unless converted to a binary (like present/not present).
Now, I can see where the normal distribution might come in when calculating p-value but the model doesn’t have to have been generated with it to do that.
It does not say what the value of the observable will equal given some combination of x’s. Regression would be a causal model if that were true.
Consider the relationship Y=mX. Any given X yields a Y exactly but that does not mean X causes Y. The relationship may have arisen due to X causing Y but by algebraic manipulation I could just as easily produce a formula where Y is the parameter that yields X. No formula is causal model in itself. though it may, or may not, describe a causal relationship.
Reality is likely not any mathematical model we impose upon it. Failing to understand this may be at the root of the issue.
There are at least three basic ways that we get stuck with such exes
I would think an ex is someone you are no longer stuck with.
Also along the same lines:
1) Desirable but what if they keep coming ’round?
2) Indeed they can be quite a drain although unless you are dead there is always time to gather more
3) That’s an odd sentiment. Why are they exes then?
DAV:
1) Then the default assumption must not be that the causality is the same from one cycle to the next.
2) I’ve never been hit by a bus. I’m 100% sure that I don’t want one to hit me.
3) It’s a very common sentiment, therefore not odd at all. We like exes that we like because we like what we like to be right.
PS: I’ve heard some exes can be sticky. Fortunately, I’m apparently coated with a Teflon-like substance I have now just named “anti-ex”. (TM, patent pending, all rights reserved, no warranty expressed or implied, no liabilities honored, your mileage may vary, do not try this at home because I’m a professional.)
PPS: why would (1) be desireable?
Because, otherwise, your current (or future) not-ex might get upset start down the road of becoming your next-ex; likely make your life uncomfortable in the process.
2) I’ve never been hit by a bus. …
A lot of moths seem attracted to flames.
3) It’s a very common sentiment …
Really? In my experience, most of those with exes tend to think of them this way:
https://www.youtube.com/watch?v=9cYoM1Rxmpg
Drat! I should have used an a-tag.
Also in re (1) there is this
I remember the big ruckus about bell curves and IQs and white folks and non-white folks from when I was a kid. It seemed silly to me even at the time, that people seemed to take it so seriously, and take such great offense. I mean, even if you believed the researchers conclusions, so what? If you were an average white guy, did you take great pride in the notion that, true, 50% of the white population was smarter than you, but only 49% of the non-white population was smarter than you?
DAV: youtube has finally joined the 21st century and adopted HTML5 for video content. Ubuntu apparently didn’t get the memo, and I’m too tired to research the required hacks, much less employ them. I’ll watch the vid tomorrow. The title already has me in stitches.
Ohhh, that’s very good. I tip my hat. It’s the darnedest thing too. Here on the left coast, there’s this hubristic belief that pedestrian right of way laws somehow annul the laws of physics — people routinely walk in front of my car without even looking before stepping off the curb. When they do look at me, it’s an indignant glare as I come screetching to a halt 10 feet from yet again demonstrating that those who likely believe in Darwin aren’t neccessarily any wiser about understanding the moral of his story.
As for me, the day I’m as dumb as a moth is the day I deserve to get squished by a bus, regardless of whether it’s on fire or not.
Milton:
Not really, but it was a brilliant attempt to distract us from the well-known fact that the size of our IQ is the least of male preoccupations. And the further well-known fact that not all men are, in any way shape or size, created equal.
Mr. Briggs,
Came across this article: To Explain or to Predict? http://arxiv.org/pdf/1101.0891.pdf (Published in the journal Statistical Science, 2010). I thought you might be, at least, interested in Section 1.5, which has something to do with the philosophy of science.
This paper briefly mentions descriptive modeling (summarizing data without explanatory inference or prediction), and discusses modeling techniques and the differences between explanatory and predictive modeling in data preparation, explanatory data analysis, the choice of variables and methods and criteria, and reporting.
One needs some statistics technical knowledge to fully understand the article. But, I think, the two interesting examples about Netflix Prize and Online Auction Research in Section 3 would give many readers a good idea of the author’s main points.
A paper worth reading twice. A must read for all statisticians, imo.
Sorry, no direct comments on this post.
JH,
Excellent point: there is a seeming difference between explaining and predicting. We’ve done these before, but not to the extent that it’s sticking.
Luckily, regression is just the technique to highlight there is no real difference between the two. What are those coefficients except minor tweaks in m? And what is m but the predictive change in our uncertainty in the observable?
But, like you suggest, this is too telegraphic. More to come.
Many years ago I came across an article that showed regression couldn’t find the Pythagorean Theorem given nothing but Pythagorean triangles….
“Many years ago I came across an article that showed regression couldn’t find the Pythagorean Theorem given nothing but Pythagorean triangles…”
Regression analysis is inconsistent with the principle of entropy minimization thus failing to reduce to the classical logic. The Pythagorean Theorem is a consequence from this logic.