
I claimed, and it is true, that all statistical problems could be written 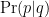
I also claimed that q often contains “I believes”, in the form of “I believe the uncertainty in p is represented by this parameterized probability ‘distribution’.” Regardless whether these beliefs are true, as long as there are no calculation errors,
So let’s separate the “I believes” from q and call them m (for “models”). Thus we have 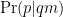
It turns out, at least in theory, that we can always deduce probabilities when p and q speak of finite, discrete things, which are really all the things of interest to civilians.2 Mathematicians, statisticians, and the odd physicist, however, insist on stretching things to limits to invoke continuity. Noble tasks, worthy goals and the only real mistake these folks make in pursuing them is anxiousness. Because the “I believes” are usually stated in the continuous, infinite forms as if given to us from on high and are not themselves deduced or inferred from the evidence on hand. And—as one of my favorite jokes has it—that’s when the fight started.3
The m’s, the “I believes”, are the cause of (rightful) contention between the two main sects of statisticians, the frequentists and Bayesians. Give you an example: p = “Tomorrow’s high temperature will be 72F”; q is any sort of data we have on the subject, and m = “The uncertainty in p is characterized by a normal distribution with parameters a and b.” The parameters of this model, as they are in most, are themselves continuous and unobservable; well, they are just fictions necessary to compute the probability of p.
Which in this case is 0 regardless of the value of a and b. That’s because a normal distribution, like all continuous distributions, give 0 probabilities to all single observables. (Don’t forget this probability is true assuming q and m.) This is why we can’t ask normal questions of normals (a pun!). You can see this is the point where adherence to a lovely theory can screw with reality. Anyway, if we want to use continuous distributions we must change our propositions so that they become answerable: let p = “Tomorrow’s high temperature will be greater than 72F”. This will have some non-zero value no matter what a and b are.
And just what are a and b? Nobody knows. There is no evidence in q or m to tell us. But since knowing what they are is absolutely necessary to solve the problem, we have to make some evidence up. Bayesians start talking about “flat” or “non-informative” or “improper” priors; some like to say “maximum entropy!” (the exclamation mark is always there). This move baffles the frequentists who say, and say truly, “You’re just making it up! How do you know it’s the right answer for this problem?” The Bayesian demurs and starts discussing “objectivity” and so forth, all different names for the same maneuver he just pulled.
So the frequentists go their own way and say, “I don’t know a or b either, so I’ll just guess them using one of several functions, or test their values against this null hypothesis.” Now it’s the Bayesians turn to demand accountability. “But you have no idea if your guesses are right in this problem! And, anyway, nobody in the world believes your so-called null hypothesis.” The frequentists retort, “Well maybe we don’t know if the guesses are right in this instance, but they will be if we do problems exactly like this an infinite number of times. And nobody ever believes null hypotheses, sort of.”
The steaming opponents—who you will have noticed ignore that both made up m out of whole cloth—leave the field of battle and head back to their encampments to produce their guesses which—surprise!—are usually not that different from each other’s. This is partly because all or almost all statisticians start as frequentists and only see the light later, so everybody uses the same kind of math, and partly because there’s usually a lot of good, meaty knowledge in q to keep people from going too far astray.
But the criticisms of both are right: from the arbitrariness of the m to the arbitrary guesses of the parameters, there’s a lot of mystery. Both sides are guessing and don’t like to say so.
The alternative? Restate the problem in discrete, finite terms and then use q to deduce the probabilities in p—if they even exist as single numbers, which most times they don’t. For most applications this would be enough. For instance, do we really care about 72F in particular? Maybe the temperature at the levels (‘below 60’, ‘between 60 and 70’, ‘between 70 and 75’, ‘above 75’) are all we really care about. After all, we can’t make an infinite number of decisions based on what the temperature might be, only a finite number. This moves gives us only four categories, some good observations in q, and we won’t be adding anything arbitrary. Everything is deduced starting with premises that make sense to us, and not to some textbook.
Well, this works. And if we really are enthusiastic, we work out all the math and then, and only then, take things to the limit and ask what would happen.
See this poorly written paper for an example of the typical “unknown probability of success”.
Next, and last, time: how do we learn about q?
———————————————————
1I’m not going to prove it here, but we don’t need information about “uniformity”, “symmtery”, “priors” or any of that stuff. See the statistics and probability philosophy papers for more details. Just believe it for now.
2I’m not proving this here either, but if you disagree I challenge you to state a measure of interest not of the categories listed about that isn’t discrete and finite.
3My wife and I were out to eat and there was a drunk at the next table. My wife said, “That’s the guy I used to date before we were married. He started drinking the day we broke up and hasn’t stopped since.” “My God,” I said, “Who would’ve thought a guy could go on celebrating for that long!” And that’s when the fight started.
Hey Matt, I am upset by your phrase “the odd physicist”. I may be eccentric, but I am not odd!
Bob,
Good thing I didn’t go with my first instinct and add the note (“of course, all physicists are odd”)…
Mr. Briggs, is’nt your q proposition a qm proposition in disguise, would’nt Hume for instance say:
q = an object k sided, etc.
m = k sided objects show only one side up when tossed.
p.s. I do agree that as it stands the probability is a quantification between propositions q and p and in this sense we may talk about logical probabilities like Stove, Keynes, etc.
I assume the mistake in the neon formula is P(A) and P(B) are not conditional. But anyone who’s been reading you long enough would know that. So… not sure I’m worthy of 10 WHOLE POINTS!
Nick,
Give that man a Kewpie doll! My heart soars like a hawk that somebody got it so quickly.
Ed,
Really doesn’t matter in that example because we’re taking the single proposition “q and m”; as long as it’s all in there, that’s enough.
Briggs’ “probabilism†forces him to restrict statistics to the toy “events†he invariably gives as examples. These are almost never of interest in finding out about the world (which is an open-ended process.) Statistical science is interested in using probabilistic information to qualify what is learned about generalizations, causes, the discovery of the Higgs boson and its properties, and so on. We don’t wish to assign priors to these claims—whatever they are thought to mean–, nor do we need to in order to find things out, and scrutinize inferences. And one more thing before I return to frequentists-in-exile, please resist the straw men he regularly (and cleverly) throws your way: frequentist error statisticians do not justify their inferences by appealing to doing “problems exactly like this an infinite number of timesâ€â€”or even to doing them again. Howlers, howlers, all of them.
Bob Kurland said: I am upset by your phrase “the odd physicistâ€. I may be eccentric, but I am not odd!
Certainly, you are. There is only one of you, and that is not an even number.
+++
Uncertainties abound, and statistical uncertainty is only one kind, and in many respect the least important kind. One really ought not accept m as given if uncertainty regarding model structure is the major source of uncertainty: is ‘normal’ a good estimate of the reality? Or is ‘extreme value’? Or…; or if it’s not even clear that the question itself is certain: Pr(X=72|EM) or Pr(71.5<X<72.5|EM) or… For that matter, as in certain models currently popular, is the evidence E all that certain? Instruments may malf, get moved, lose calibration, etc.
The only thing we can know for certain is that we know squat.
Briggs,
A bit OT, but probably something you’ll like.
http://www.nature.com/news/scientific-method-statistical-errors-1.14700
Some evidence that little Ps are about to head wee-wee-wee all the way home?
Mayo, I am not an expert in this field but please bear with me as there is something that I do not understand in your last comment. First a side issue: in physics when a new method of analysis is developed, let’s say Lagrange versus Newton, it is customary to test it on well known problems to confirm that the expected answers are obtained. Let’s call these the toy problems. When we are satisfied as to the rigor of the new method we turn our attention to new problems that are difficult to solve by the old method but which are ideally suited by our new approach. If, however, our new method can not solve the toy problems it is toast and must be rejected. Returning to the issue at hand, you seem to be saying that the statistical method that you prefer can not solve the toy problems favoured by Briggs, but that despite this we should still trust it to solve much more complicated problems. Have I missed something and if so what?
Matt, have you seen this ?
http://www.nature.com/news/scientific-method-statistical-errors-1.14700
In Nature of all places, which stopped being a source of reliable information a good few years ago.
“P values, the ‘gold standard’ of statistical validity, are not as reliable as many scientists assume.”
…..
“It turned out that the problem was not in the data or in Motyl’s analyses. It lay in the surprisingly slippery nature of the P value, which is neither as reliable nor as objective as most scientists assume. “P values are not doing their job, because they can’t,†says Stephen Ziliak, an economist at Roosevelt University in Chicago, Illinois, and a frequent critic of the way statistics are used.”
The denominator in the image is incorrect. It should represent the sum of all numerators.
Frankly, I find it tiring to need to keep saying P(A|whatever). Most of the books I have use it up front then dispense with it; substituting P(A) in its stead. It’s like having to say he or she wherever a pronoun might be used. Cumbersome.
—-
Briggs,
You seem occupied today. C’mon admit it! You’re a closet Beatles fan and you were preparing for the Beatles Grammy tribute tonight.
BTW: I know the formula in the sign is often written that way but P(B) in the denominator is just plain confusing. I prefer using something like P(D) to emphasize it’s a normalizing term. Perhaps, multiplying by a normalizing constant would be better notation.
I think this guy has Briggs envy.
http://www.nature.com/news/scientific-method-statistical-errors-1.14700
DAV,
How about ?
Outside of dice and other toys, can anyone really quantify the probability seeing the event under “any hypothesis”?
Your neon sign is the correct statement of the simple form of Bayesian Theorem which can be proven from the teachings of measure theory probability or axiomatic set theory, and etc bfd. Perhaps the mistake is that there is no statement that P(B) is not equal to zero, or the vertical conditional line symbol is not truly vertical making the top left hand side mean the probability of set B exclude set A?
“Your neon sign is the correct statement of the simple form of Bayesian Theorem which can be proven from the teachings of measure theory probability or axiomatic set theory, and etc”
The issue is that Briggs rejects any ontological interpretation of probability in favour of the epistemological. For Briggs, probability cannot be used as a model of what *is*, only of what people are able to *know*. (Hence him talking about “evidence, or premises, or data, or data-plus-model, whatever you like to call it.”) You cannot know what’s there directly, you can only do so through the filter of finite sensory observation.
The measure theory, on the other hand, builds an idealized mental model of some domain over which we have an omniscient God’s-eye view, since we made it up ourselves. Thus, we don’t need any sensory observations to learn about what’s there, since we completely defined what’s there ourselves.
The confusion arises from mixing the two. The standard approach is to build an exactly specified ontological mental model that reproduces observation, and assume that if it does so well enough we won’t go too far wrong if we assume our mental model describes what is actually there. The step is so familiar we do it without commenting on it, or sometimes even noticing. Since Briggs rejects the *very concept* of probabilities in an idealized mathematical model of the world, all one can do is count and calculate with sensory observations. You can’t act as if they’re reflecting any sort of true reality.
I have to say, to me it sounds very much like the sort of talk that gives philosophy a bad name, but the viewpoint certainly has its fans.
NIV,
I can’t understand your criticism. Epistemology just is different than ontology, and logic is a matter of the former and not the latter.
Hey, what’s the probability World War II would not have happened if England did not join WWI? That’s a question many are debating this centenary. If you even try to have a thought about this, you aren’t thinking ontologically, but epistemologically. Only probability as logic can handle counterfactuals—since there is no ontology, and can be no ontology.
Task number two: write and justify any unconditional probability. I’ll wait here. (This is why the equations above a wrong; they express unconditional probabilities.)
This can’t, of course, be done. Again, probability is matter of epistemology.
Trying to answer questions like these (or understanding how to answer questions like these) is what gives philosophy a good name.
Thanks for the reply but for me too many shells in that onion. I think few working statisticians build models without data, Baysians build models of some percent data and some percent pre-existing bias. A useful belief is that our regressions and AR(x) models and such estimate what is trend of data and what is error in observing data. Usually they do a very good job (if there is a trend.) Regardless of the two camps of boring frequentists and cool baysians a theory of probability is pretty useless if it can’t predict how many times you get heads after many tosses. Both philosophies can do this.
Define X the set of all possible events. Define y not an element of X as an impossible event. y is independent with respect to X. Thus y is not conditional on X. P(y) is not conditional on X.
Joseph Blieu,
This is only a fragment of a thought. What can you possibly mean by “X the set of all possible events”? And then you cut your own throat with (I’m paraphrasing) “Y is an impossible event.” To say that means the probability of Y is NOT unconditional. It is conditional on whatever evidence which proves Y’s impossibility.
You can (try this) easily construct Ys which are impossible conditional on some premises but possible or even certain given other premises.
” I think few working statisticians build models without data”
Are you talking about ‘theory’ or ‘applied’ statistics?
“What can you possibly mean by “X the set of all possible eventsâ€?”
The set of all events that are possible.
Either an event is possible or it isn’t. It can’t be half-possible. So if you take all the events for which the true answer is ‘yes’, and exclude all the events for which the answer is ‘no’, you get the set of all possible events.
“It is conditional on whatever evidence which proves Y’s impossibility.”
No evidence can *prove* impossibility. But not being able to *know* that something is impossible does not mean that it *can’t* be impossible.
In models, possibility or impossibility is *asserted*. In reality, we simply don’t know. The relationship between the two is an imperfect approximation.
NIV,
No, all wrong, quite, quite wrong. Given “men cannot fly” the probability “NIV is a man and NIV flies to his perch” is 0. It is impossible.
“The set of all events that are possible” is meaningless—without conditioning it on some other evidence/premises.
Even if trivial if the set of impossible events is null it is not conditional on the set of possible events.
“Given “men cannot fly—
That’s just a model of reality, about which you have *asserted* that men cannot fly. Inside that model, a man flying is impossible.
But reality is independent of all our models, and has its own rules. It is either true or not true that men can fly or that I can fly. There is no choice of premises or assumptions involved, and it is true or not true irregardless of whether anybody has any evidence for it or not.
If we’re talking about models, then the assertions used to define the model don’t need to be included in its formulas. They’re unconditionally true, *in that model*.
In Peano arithmetic, the formula ‘1+2=2’ is unconditionally true. I don’t have to write ‘1+1=2|Peano Axioms’ every time when I’m working in that system. I would only have to do so when I’m working in a meta-system in which they might not be true. It’s not an error to put it in, but it’s redundant.
On the other hand, if we’re talking about what agents can *know* about the world they live in – epistemology rather than ontology – then everything is conditional on a long string of assumptions for which the agents can have no proof – only evidence that makes it seem more or less plausible. And every chain of Bayesian reasoning is ultimately built on priors for which there can be no evidence or justification. It happens to work, but we’ve got no guarantee that it must.
There is an ontological fact of the matter about which we can only obtain indirect epistemological evidence. Separately, we build mental models of worlds and modeled observers within them, in an attempt to understand the relationship between what we see and what is. In both, there is a distinction between the true ontological probability, and the epistemological estimate of it that is all an observer can make. When mathematicians talk about P(A) and P(B), they’re talking about the ontological part of a model – and inside that model, it’s perfectly valid notation. But such probabilities are not accessible to observers, only those with the God’s eye view.
Mathematics tells us how much modeled observers can deduce about modeled absolute probabilities, and how. We then apply the same techniques to *actual* observations in the real world, and hope that this tells us the same sort of things about reality.
Aaargh! I can’t type straight! That should have been ‘1+1=2’, obviously.
Baysians build models of some percent data and some percent pre-existing bias.
I think it was J. Stuart Hunter who said that in using statistics, “Don’t forget everything else you know.” Prior knowledge of how, for example, a material behaves or what the results of previous investigations have shown is not the same kind of thing as “pre-existing bias.” Indeed, 50 aluminum beverage cans arrayed in rank and file is not the same thing (dare we say) ontologically as 50 swatches of fabric cut cross- and length-wise along a bolt of cloth. Or 50 surface air temperatures measured at the nodes of a grid.
Either an event is possible or it isn’t.
Can parallel lines intersect? The truth is conditioned on whether one is using Euclidean plane geometry or spherical geometry, or Riemannian, etc. But to say that Pr(1+1=2|”Peano”) is unnecessary does not mean that the truth of 1+1=2 is unconditional. It simply means that we usually don’t bother stating the conditions. This is harmless in daily life, but might be problematical when considering switching circuits. There are times when it is worthwhile considering what unspoken assumptions we are making, lest we be caught up in their snares.
+++
“Can parallel lines intersect? The truth is conditioned on whether one is using Euclidean plane geometry or spherical geometry, or Riemannian, etc.”
Quite so. Those are all mathematical models. They are built to emulate the properties of spacetime, so the real question is: Does the geometry of spacetime include parallel lines? Either there are or there aren’t.
But each model is a self-contained definition of ‘truth’. If we’re using spherical geometry, then there are no parallel lines. It’s not conditional on anything. It’s simply true. If we’re working in spherical geometry, then geometry *is* spherical.
It only makes sense to say it is conditional when we’re working in a meta-system that includes spherical, Euclidean and Riemannian geometries as special cases. *Then* you can condition things on the choice of geometry, because you actually have a choice. It’s not the case that one is true and all the others false.
If you start allowing different axiom systems to get mixed up, then you can’t say things like P(A|B) *either*, because the concept of a conditional probability depends on axioms and definitions itself, which can of course vary. Even for those systems where it is defined, its numerical value could change. (If it even is a number.)
You can’t make statements like ‘all probabilities are of the form P(A|B)’ because that’s ‘conditional’ on a particular model of probability and logic. Conditionality itself is ‘conditional’ on some definition of what you mean by the word. Any sort of reasoning or discourse becomes impossible, because everything is dependent on an external framework of logic and experience for its validity, which you can’t include in the framework itself without getting into circular reasoning.
I regard this sort of infinite regress of definitions as a sort of solipsism: technically valid, but pointless arguing about because it’s not of any practical use.
“There are times when it is worthwhile considering what unspoken assumptions we are making, lest we be caught up in their snares.”
I agree. But we also mustn’t get so caught up on one particular set of invalid assumptions that we miss all the other things that can go wrong with an argument. Sometimes assumptions and simplifications can be made safely – and we risk missing the real cause of an error by obsessing over some innocent simplification elsewhere in the argument that really has nothing to do with it.
Thinking we’ve spotted the trap can make us overconfident.
I can’t understand your criticism. Epistemology just is different than ontology, and logic is a matter of the former and not the latter.
I agree that ontology and epistemology are different, but I think logic can handle both, albeit with slightly different rules.
Hey, what’s the probability World War II would not have happened if England did not join WWI? That’s a question many are debating this centenary. If you even try to have a thought about this, you aren’t thinking ontologically, but epistemologically.
If you’re asking “what’s the probability of it not happening?” then there is a definite answer, but we cannot know what it is.
However, this definite answer is what our epistemic estimates are attempting to approximate. It’s what the conversation is about.
Only probability as logic can handle counterfactuals—since there is no ontology, and can be no ontology.
Not necessarily. There are ontological models of counterfactuals – in particular the Everett-Wheeler interpretation of quantum mechanics (aka ‘Many Worlds’ although that’s a misnomer). Everything that *can* happen *does* happen, but in a superposition where the individual components don’t interact with one another, so we can’t see all the other possibilities happening.
One could argue that strictly speaking this means that there are no counterfactuals, since it *does* actually happen somewhere – we just can’t see it. But I think it would be fair to say that it handles what we usually think of as counterfactuals in an ontological way.
Task number two: write and justify any unconditional probability. I’ll wait here. (This is why the equations above a wrong; they express unconditional probabilities.)
When an observable corresponding to the discrete-spectrum Hermitian operator A is measured in a system with normalised wavefunction f then the probability of observing a given eigenvalue of A is equal to the squared amplitude of the scalar product of f with the corresponding eigenvector. It’s an axiom of quantum mechanics – a mathematical model – and is ‘true’ by assertion.
(Or if you use the Everett-Wheeler model, it can be explained as consequence of certain other axioms/assertions.)
There are ontological probabilities (about what actually happens) and epistemological probabilities (about what we can know). We can only get access to ontological probabilities in models of reality – never in reality itself. We can get access to epistemological probabilities in both models and reality.
Although the two concepts are superficially similar, and follow the same algebra, they are conceptually very different things. Some people refer to the former as ‘Bayesian probability’ and the latter as ‘Bayesian Belief’, just to make the distinction clear. (The literature on ‘Bayesian Belief Networks’ is extensive).
Bayesian Belief is subjective – it depends on what you know and what your priors are, and it can vary from person to person or over time. It frequently doesn’t agree with the outcomes of experiments regarding the frequency of events. Bayesian belief is an epistemological approximation of an ontological probability, and is the thing you keep on talking about.
But there are ontological probabilities too. Or at least, there are in mathematical models like quantum mechanics. Whether it’s the way reality really works is something we can never know, as this is information we would have no access to even if it did. In that sense, and regarding reality, the epistemic Bayesian Belief is all we’ve got.
write and justify any unconditional probability. I’ll wait here.
When an observable corresponding to the discrete-spectrum Hermitian operator A is measured in a system with normalised wavefunction f then the probability of observing a given eigenvalue of A is equal to the squared amplitude of the scalar product of f with the corresponding eigenvector.
Pr(A|B*C)=squared amplitude of the scalar product of f with the corresponding eigenvector
A = observing a given eigenvalue of A
B = observable corresponding to the discrete-spectrum Hermitian operator A
C = a system with normalised wavefunction
Looks conditional.
YOS,
B and C aren’t events.
I guess if you can prove bayesian theorem from axioms and theorem is wrong then the axioms are wrong. Kolmogorov was fool to create such a system and we need new axioms and University Stat Departments should close for peddling such nonsense. If a theory is falsified, reject it, don’t put on more lipstick. I think that in order to survive such a fundamental philosophical examination I would propose the axioms may be 1. If you see something occur the probability that it has occurred is 1.0. 2. If something has not occurred the probability of it’s occurrence is undefined. This will eventually be rejected because a philosopher will say that if an event is observed we still don’t know if it actually happened, so the only truth man can find is that he will never know anything, then we can stop thinking and see if, say growing food is better than not growing food even though we do not know the probability that food exists.
Re: Mr. Olde Statistician,
“Don’t forget everything else you know.†Prior knowledge of how, for example, a material behaves or what the results of previous investigations have shown is not the same kind of thing as “pre-existing bias.â€
I am sorry, I can see that “pre-existing bias” is a negative term and I did not intend it as an insult. Like in Quantum Mechanics the Matrix and Schrodinger methods give the same answer almost all the time so do Frequentist and Baysean Stats. Meta analysis of previous data sets is a similar situation.
B and C aren’t events.
So what? The probability is still conditioned on prior assumptions.
“So what? The probability is still conditioned on prior assumptions.”
So the probability function P( ) is a mapping from a sigma algebra of *events* to the [0,1] Real interval. If they’re not events, expressions like P(A) and P(B) can’t apply.
And in this case, they’re not prior assumptions, they’re the arguments of a function. When we talk about the function f(x) = x^2, x is not an ‘assumption’ on which the value of f is ‘conditional’. We’re not assuming any specific value for it, it’s not a proposition with a probability. Likewise, A and f are just the arguments of a function that gives the probability distribution of the observable.
Otherwise, we would have to say that P(A|B) was conditional on the arguments A and B, and should therefore be written P(A|B)|A,B, or something of the sort. (You can easily get into another infinite regress, here.)
If the statement is conditional on anything, it’s conditional on the axioms of QM, of which this is one, (the Born rule). The axioms are propositions for which P(Axiom) = 1 by definition. But as I said, it’s not necessary to include them in formulas of a system since there’s no possibility of the system’s axioms being false. They’re true by definition/assertion within that system, so it’s redundant.
And here I always thought probabilities applied to the truth of propositions.
NIV,
I can see your classical training, but it is wrong.
“Pr(Axiom) = 1 by definition” is false. There is no such thing as unconditional truth or probability.
Pr(Axiom | Intuition) or Pr(Axiom | Faith) = 1, but you need something.
NIV,
Let me give a very slight spin.
In the theory of probability measure, it’s quite obvious that all sets involved in a probability formula are tacitly assumed to lie in a sigma-field F, behind which the background information or premise is hidden and often not stated in probability statements.
So, it wouldn’t bother me to say that the unconditional probability as a special case of the probability of a conditional on certain tacit assumptions.
Whether to add an addition notation F in the probability statement is really not an issue at all in the study of probability theory.
It might be big deal to Briggs because he want to emphasize to the interpretation that probability is a logical relation between propositions and is constrained by evidence.
If Briggs insists on writing P(A|B,K)=P(A&B|F)/P(B|K), but then P(B|K)=P(B&K)/P(K). That is, P (K) is needed to determine the value P(A|B,K), but it lacks value because it’s not constrained by evidence as required in the logic probability interpretation. How does logical probability explain this problem?
“Pr(Axiom | Intuition) or Pr(Axiom | Faith) = 1, but you need something.”
No you don’t. What you’re *given* is the axioms, so if you like, you get Pr(Axiom|Axiom). The axioms are true by definition. That’s what axioms *are*: propositions taken to be true without proof or justification.
The formulas of an axiomatic system don’t have to explicitly include their conditionality on the axioms. You can say simply ‘A v ¬A’ as a true formula, without caveat.
Or you could also use the proposition T, representing truth in logic. P(X|T) = P(X & T)/P(T) = P(X)/1. Any statement at all that is known to be true will work.
I agree that there is an important distinction here, and that when one is talking about the real world, all probabilities *are* conditional. But the expressions P(A) and so on are talking about *theory*. We can make our *own* rules up.
Incidentally, intuition and faith aren’t events, either.
NIV,
Nope, not even close. If somebody asks you why the axiom is true, you will at least say Pr(Axiom|definition) = 1, but more likely you will say Pr(Axiom|intuition) = 1. You can’t have something from nothing.
If someone asks *me*, I’d say Pr(Axiom) = 1. *You* might say something different. 🙂
And it’s not getting something from nothing. In an axiomatic system, you *start* with the axioms, so they’re always there.
NIV,
Hence the danger of either reification or turning a blind eye. And your statement on the axioms nonsense that you don’t even believe. You believe the axioms based on what your intuition tells you of them, or even because somebody told you to believe them (the “definition” route).
You’re mistaking your mistake in notation as a logical discovery.
I’ll bet $10 that next time some newbie asks you, “NIV, why is this axiom true?” you will not just insist, “Because Pr(Axiom) = 1.”
” You believe the axioms based on what your intuition tells you of them, or even because somebody told you to believe them (the “definition†route).”
It’s more akin to what they usually call ‘suspension of disbelief’. When you’re engrossed in a book or a film, you temporarily forget that it is fiction, and consider statements true or false as defined by the narrative. Is it true that Gandalf precipitated the downfall of Sauron by visiting a certain hobbit in the Shire? The sort of smart-Alec who answers “No, because Gandalf doesn’t exist” is simply being annoying. The mind builds a ‘frame’ or context, in which truth of propositions is judged according to its own internal rules. Seen from the inside, it’s all true. Seen from the inside, there is no outside. It’s a self-contained artificial universe.
Axiomatic mathematical systems formalise this human habit. The system is defined by its axioms and rules of deduction, which are taken from the beginning to be true without need for justification or proof. Seen from the inside, there’s no other way things could be. They don’t come from anything else; they’re what you use to generate everything else.
It has to be this way because of that rule you cited “You can’t have something from nothing”. If you start off with an empty axiom list, it remains empty. You can’t create any new theorems or anything else without something to start from. They’re not derived from evidence, because you’ve got no rules or principles yet by which to do the derivation. The axioms are where you start.
So if anyone asks me “Why is this axiom true?” My answer would actually be “Because it’s an axiom.” Axioms are true because they’re axioms. Theorems are true because they can be derived from the axioms via a chain of valid logical transformations. They’re as absolutely true as 2+2=4 is absolutely true. If you go around saying it’s only probably true, or ‘it depends’, people will think you’re weird.
(Granted, there are other axiomatic systems where it’s not. But while you are working in one where it is true, which most people are almost all of the time, then it is absolutely true.)
And while axiom systems were originally chosen on the basis of intuition – Euclid regarded them as so obviously true there could be no argument – modern mathematicians don’t think like that. I used to do a lot of work in finite geometries, which obey many of Euclid’s axioms except that they only have a finite number of points and lines in them. The entertainment was in seeing how much of ordinary geometry you could carry across. And we didn’t pick the axioms because they were intuitively obvious – they weren’t! – we picked them often just to see what would happen.
If you start off with any consistent set of axioms, and negate one of them, you get another equally consistent set of axioms – a sort of “alternative mathematics” with almost the same rules but not quite. Understanding what is true in the new system is enlightening about what theorems and observations are co-dependent. The mathematics you get *with* the Axiom of Choice, or the Riemann Hypothesis, is subtly different to the mathematics you get without it.
If I use the Axiom of Choice in a proof, and somebody asks me “Why is that true?” I can only say “Because I took it as an axiom.” I can give justifications for why the axiom is intuitively plausible, but then I can just as easily give justifications and evidence for why it’s implausible, too. At the end of the day, the justifications are irrelevant. It’s an axiom, so we can swing either way with equal consistency. I chose to make it true. It’s true because I said so. There’s nothing more to support it than that.
Or to pick another example, consider classical/Newtonian physics. Now that contains ‘axioms’ that I know are plain wrong! But while working in the Newtonian paradigm, I suspend disbelief, and reason as if those principles were true. The force of gravity applied to the Earth by the sun is equal and opposite to the gravitational force applied to the sun by the Earth. Except how does the sun know which way to be pulled, when the Earth is 8 light-minutes away? Is it pulled towards where the Earth is now, or where it was 8 minutes ago? The difference matters! But in the Newtonian paradigm, we don’t even think about it. Forces are equal and opposite, and gravitation acts instantaneously at a distance: they’re absolutely true. And I feel absolutely no cognitive dissonance when doing it.
When you look closely at human reasoning, it’s actually a lot more peculiar than one might think.