
This mistake makes sense because sometimes the relative frequency matches the probability. But it does not always do so. For instance, if in a bag there are n objects just one of which is labeled X and just one will be pulled out, the relative frequency of objects labeled X is 1/n which matches the probability that this object is drawn. The existence of the object matches our knowledge of it.
But if our premises are that “All Martians wear hats and George is a Martian” relative to the proposition “George wears a hat”, then there is no relative frequency—there is no ontology (to speak loosely and in the form of computer scientists); there are no Martians wearing hats and therefore no Martians named George. But there is a probability (which equals 1). “All” in the premises may be changed to “Some” or “Just 3 of n” or whatever and the conclusion that no relative frequency but a probability exists remains the same. And (of course) no counterfactual proposition has a relative frequency, but most (all?) can have a probability.
Suppose you don’t know, you have a “blank epistemology”, of the number of objects labeled X in the bag, but you at least know that each object has the possibility of being X. This is akin to suspecting a “loaded” coin, or in “trials” where there will be a defined success (the X) and failure, or whether an elementary particle in this field and measured in that way will show a certain property1, or to any situation where the concern is one thing whose presence is contingent. It is easy to show that there is a still a probability of “drawing” an X (which is 1/2). But while there exists (at least in the here-and-now fixed bag) a relative frequency, it is unknown and therefore cannot be equated with the probability.
The relative frequency in a (say) drug “trial” is trickier. The number of elements (the “sample size”) will be finite. Of course, the relative frequency will eventually be something, say m/n successes, but at no point until we have reached the end will we know what the relative frequency is. Yet at each point the probability is still calculable (in the same way as discovering the initial 1/2), and of course eventually becomes the relative frequency—relative to the proposition “This element in the experiment was X” and knowing only there were m successes and n possibilities. But then the probability is also 1 relative to the same proposition but this time including all the knowledge from the trial (because we know whether each individual was a success or failure).
Now suppose we want to extrapolate what we have learned from the trial—of which everything is known, thus any proposition relative to this knowledge will have extreme probabilities (0 or 1) or any probability (propositions which have no logical relation to the trial but which are contingent will have the interval from 0 to 1). If we want to say something about the next n people before they take our drug, again there will eventually be a relative frequency but it is now unknown. Yet the probability is known (in the same manner as before). And again, once we reach the end of the n, we know everything there is and our probabilities are once again extreme or any probability (the interval (0,1)).
The next abstraction is to assume the trial’s (or even initial) results will be with respect to an infinite population: n goes to the limit, a mathematically desirable state. But nothing changes. We are still able to discover a probability at any point before the “long run” expires. We will, of course, wait for forever and a day before a relative frequency (of the entire set) exists. Once the Trump of Doom sounds and time ends, we will have everything we need to know and the probability and relative frequency will match. But nobody (at that point) will care.
How do we know this? The strong2 “law” of large numbers states that (or, in other words, it can be proved beyond all doubt that):
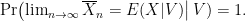
which is to say the probability that the growing sample’s relative frequency (the average) equals the “expected” value of an observation given some evidence V is 1, but only at the limit. Notice we have used the limit twice, one time boldly and the other hidden in 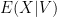
———————————————–
1There is a healthy debate whether quantum theory is epistemological or ontological, or a mixture of the two. See inter alia the work of Anton Zeilinger (here or here). Zeilinger has scientist hair, so you know you can trust him.
2The difference between the strong and weak laws for this discussion are negligible.
>i>There is a healthy debate whether quantum theory is epistemological or ontological,
Given your definition of ontology, it’s hard to see how any scientific theory could be ontological as the door is forever open to the theory being wrong.
With respect to QM, isn’t it the interpretation that claims randomness is an inherent property instead of a statement of our limitations vs. an actual claim by the theory?
—
BTW: in the previous post I tripped over the switch from ontology to ontological but, if you were talking about intent of the theory, isn’t QM attempt to tell us what is vs. what we could know?
DAV,
Well, exactly so: unless we can prove physical theories in the same way we prove metaphysical theories (like mathematics, logic, theology, etc.) then there is a certain kind of doubt. Speaking briefly, that’s the nature of contingency.
Take our best physical theory. Still plenty of “out-of-the-blue” parameters which are experimentally applied. Physics won’t reach rock certainty until all of these can be deduced in the same manner as any metaphysical theory.
More on QM later.
I’d like to agree with Briggs against DAV. Without getting into discussions about the likes of Popper and Kuhn, surely the whole point of science is that it changes in the face of new evidence? Admittedly I gave up on ontology many years back and find epistemology to be more accessible.